Lonestone est une agence qui conçoit et développe des produits web et mobile innovants intégrant de l'IA.
Nos experts partagent leurs expériences sur le blog. Contactez-nous pour discuter de vos projets !
Héberger une IA en France : performance & RGPD
Créer un SaaS IA est déjà un défi en soi. L’héberger en France, tout en maintenant des performances solides et des coûts maîtrisés, élève encore d’un niveau la complexité pour les équipes produit et les décideurs digitaux. Entre un RGPD de plus en plus exigeant, des enjeux de souveraineté numérique très politiques et la réalité parfois ingrate des performances des modèles d’IA, chaque choix d’architecture devient un arbitrage serré.
Car dans les faits, vous voulez tout à la fois : un SaaS IA rapide, hébergé en France, conforme, et finançable à moyen terme. Mais un modèle hébergé hors UE peut poser des questions de conformité, quand une infrastructure 100 % française risque de faire exploser la latence ou la facture GPU. Mal pensée, l’architecture peut finir par saboter la promesse même de votre produit.
Les vrais enjeux de l'hébergement IA en France (au-delà du RGPD)
Performance vs souveraineté : le dilemme des décideurs
Localiser les données en France n’est qu’une petite partie de la conformité. L’enjeu majeur reste l’expérience utilisateur. Un chatbot conforme qui répond en huit secondes n’est pas un chatbot utile et encore moins un produit adopté.
Prenons un exemple simple : un assistant IA pour le service client. Hébergé sur une infrastructure parisienne mais s’appuyant sur un modèle GPT-4 via API américaine, son temps de réponse monte à 3,2 secondes. En optant pour un modèle équivalent hébergé en Europe, on retombe à 1,4 seconde. Une différence qui paraît minime… mais qui change tout. Car dans la latence, les millisecondes s’additionnent vite, jusqu’à dégrader la valeur perçue du produit.
Outre la latence, plusieurs facteurs techniques entrent en jeu :
Disponibilité GPU : la variété d’instances V100/A100/H100 reste plus restreinte en France que chez les hyperscalers US, même si l’offre progresse rapidement (OVHcloud, Scaleway…).
Support technique : les équipes IA sont moins nombreuses que chez AWS, GCP ou Azure.
Écosystème : moins d’outils natifs pour monitorer et optimiser les workloads IA.
Zoom technique. Une requête IA combine résolution DNS (20–50 ms), handshake TLS (100–200 ms), inférence (200–800 ms) et retour. Chaque saut géographique ajoute 50–100 ms. Sur un chatbot temps réel, cette accumulation peut facilement dépasser le seuil psychologique des deux secondes.
👉 Règle d’or : la conformité ne doit jamais se faire au détriment de l’usage.
Un produit parfaitement conforme mais pénible à utiliser n’apporte aucune valeur business.
Impact financier réel : ce que cachent les grilles tarifaires
Pour se faire une idée concrète des écarts de coûts, prenons un scénario illustratif : un SaaS IA avec un volume important de requêtes mensuelles et un besoin ponctuel en GPU dédié pour l’inférence. Dans ce cadre, une simulation interne fait apparaître trois ordres de grandeur :
Scénario 100 % US (AWS + OpenAI) : ~41 000 €/an – performances optimales, conformité plus complexe à gérer
Scénario 100 % France (OVHcloud + modèles hébergés localement) : ~54 000 €/an – souveraineté maximale, mais coût d’infrastructure plus élevé
Scénario hybride : ~33 000 €/an – équilibre intéressant entre performance, conformité et budget
Dans cet exemple, la différence entre les scénarios extrêmes représente l’équivalent d’un poste junior à plein temps — un impact non négligeable pour une startup encore en phase de structuration.
Ces montants restent bien sûr dépendants du niveau d’usage, du choix des modèles IA et des besoins réels en capacité GPU. Ils intègrent néanmoins des postes souvent sous-estimés : montée en compétence des équipes, mise en place du monitoring spécifique aux workloads IA, migration progressive des données et, surtout, temps de développement supplémentaire lié à l’adaptation de l’architecture.

Ces montants sont des ordres de grandeur issus d’un scénario type. Ils varient selon l’usage réel (volumétrie, modèles IA, charge GPU, fréquence des requêtes).
3 architectures éprouvées pour héberger votre IA en France
Solution 1 - Cloud hybride : le meilleur des deux mondes
L’architecture hybride consiste à stocker les données sensibles en France tout en exécutant l’IA là où elle est la plus performante. Cette approche nécessite une conception soignée, mais offre une flexibilité remarquable.
Dans ce modèle :
les données restent chez un hébergeur français (OVHcloud, Scaleway),
un cache Redis synchronise les données nécessaires,
les LLM, pipelines RAG ou copilotes métiers peuvent s’exécuter sur AWS ou GCP Europe,
les microservices IA communiquent via API ou via un protocole standardisé comme le Model Context Protocol (MCP).
Cette option convient très bien aux SaaS B2B européens nécessitant performances globales et conformité stricte.
Cas réel (anonymisé).
Fintech parisienne, 50 000 dossiers/mois : données sur OVHcloud, scoring sur AWS Europe. Résultats : conformité préservée, temps de traitement divisés par deux, et 35 % de réduction de coût.
Stack typique : Istio/Linkerd, WireGuard/IPSec, Kong ou AWS API Gateway, Jaeger + Prometheus.
👉 Pour 70 % des SaaS, c’est l’option la plus équilibrée.
Solution 2 - Full France : quand la souveraineté est non-négociable
Certains secteurs n’ont simplement pas le choix : santé, défense, finance critique, administrations, ou grands comptes qui imposent une souveraineté totale. Dans ces cas, l’hébergement full France n’est pas seulement un choix technique, mais un impératif contractuel.
Bonne nouvelle : ce choix n’est plus synonyme de performances médiocres. OVHcloud propose désormais des A100 compétitifs ; Scaleway simplifie l’expérimentation grâce à des APIs propres ; Orange Business fournit un support entreprise exigeant ; et 3DS Outscale coche toutes les cases liées à la certification SecNumCloud, indispensable dans certains marchés.
Cependant, une migration full France exige une approche méthodique. Les premières semaines servent à auditer les dépendances, identifier les composants critiques, mesurer les besoins GPU et anticiper l’impact sur les modèles IA. Viennent ensuite la migration des environnements de développement, les tests de charge intensifs, la bascule progressive du trafic (5 %, puis 25 %, puis 100 %), puis l’optimisation finale.
La performance en full France dépend surtout de l’ingénierie : sharding intelligent, caches multi-niveaux, optimisation des LLM via quantification ou pruning, gestion fine du traffic shaping… Autant de leviers qui permettent de maintenir des temps de traitement compétitifs même sur infrastructure française.
L’hébergement full France est donc totalement viable — à condition d’être rigoureux, patient et structuré.
Solution 3 - Edge computing : distribuer pour optimiser
L’edge computing représente l’avenir des applications IA les plus sensibles à la latence : assistants vocaux, traduction temps réel, copilotes embarqués, IoT intelligent, applications mobiles nécessitant une réponse instantanée. Le principe est simple : rapprocher l’inférence de l’utilisateur, tout en conservant les données sensibles en France.
Dans ce modèle, les données maîtres restent centralisées sur une infrastructure française. Les modèles d'inférence — souvent optimisés ou allégés — sont déployés sur des edge locations européennes. La synchronisation s’effectue en temps réel et peut même intégrer des techniques d’apprentissage fédéré pour améliorer les modèles sans rapatrier les données.
L’exemple le plus parlant est celui d’une application de traduction vocale instantanée déployant ses pipelines IA dans douze edge nodes européens : traduction en moins de 800 ms depuis n’importe où en Europe, données centralisées en France, conformité native.
Cette architecture repose sur des technologies de conteneurisation avancées : Kubernetes distribué, ONNX Runtime ou TensorFlow Lite pour optimiser les modèles, service mesh pour orchestrer le routage, et une stack de monitoring distribuée pour garder en vue l’ensemble de la chaîne.
Roadmap pratique : migrer sans casser votre produit
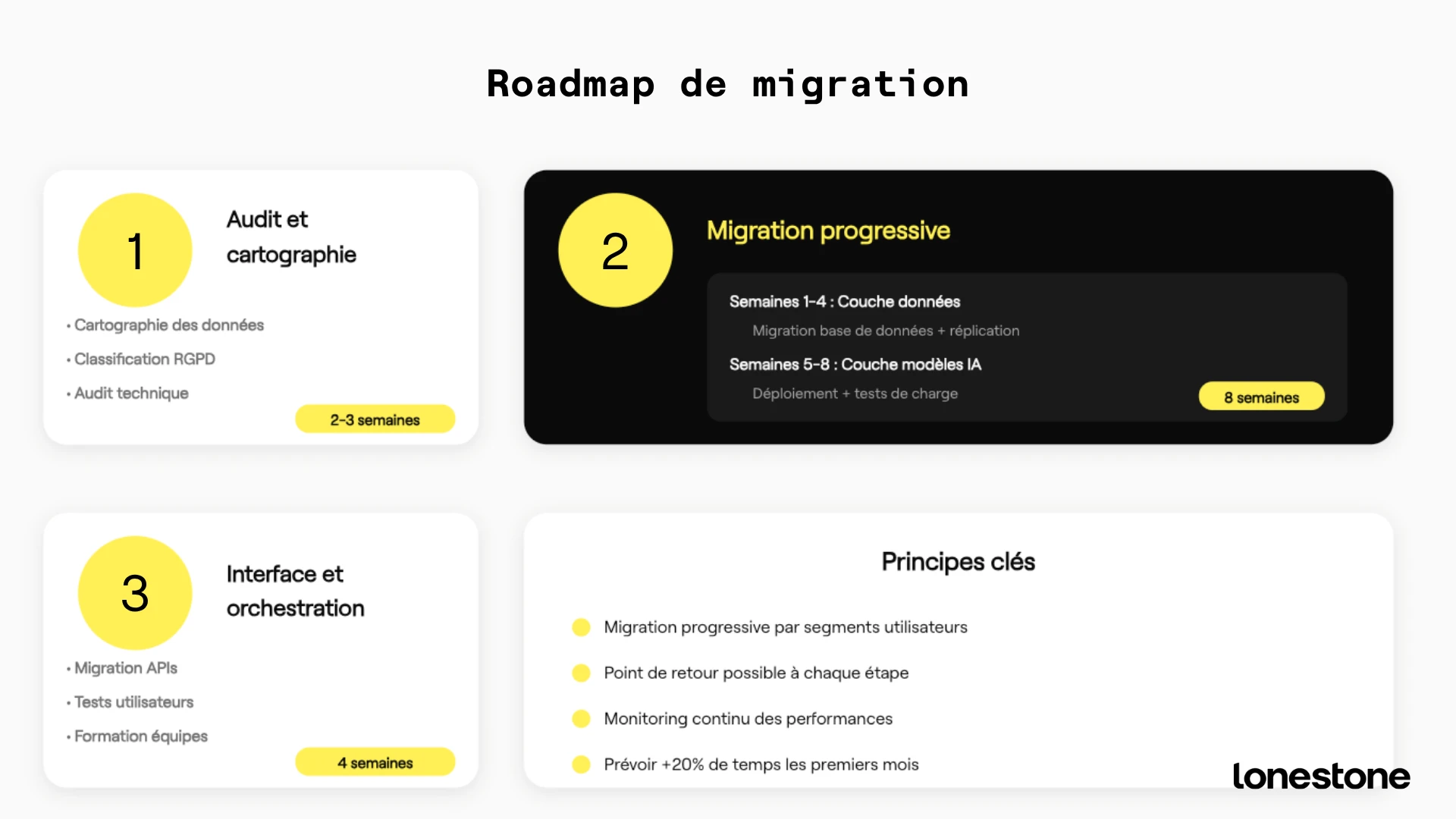
Phase 1 - Audit et cartographie de vos données
Toute migration réussie commence par une compréhension fine de l'existant. La cartographie des flux de données constitue l'étape fondamentale, souvent négligée, qui conditionne la réussite de l'ensemble du projet.
La classification des données suit une logique à trois niveaux :
Données critiques RGPD : identifiants personnels, données biométriques, historiques comportementaux → hébergement France obligatoire
Données pseudonymisées : analytics anonymisés, métriques d'usage, logs techniques → hébergement flexible possible
Données publiques : modèles pré-entraînés, datasets open source, configurations → aucune contrainte géographique
L'audit technique doit évaluer précisément le volume de données par catégorie, analyser les patterns d'accès et la fréquence d'utilisation, identifier les dépendances techniques vers des APIs externes ou modèles propriétaires, mesurer les contraintes de latence par cas d'usage, et documenter les exigences de rétention et d'archivage.
Les aspects juridiques nécessitent une attention particulière. Il faut vérifier minutieusement les clauses contractuelles avec tous les fournisseurs d'APIs IA, documenter exhaustivement les transferts internationaux existants, identifier précisément tous les sous-traitants impliqués dans la chaîne de traitement, et prévoir les procédures techniques pour le droit à l'effacement et la portabilité des données.
Cette phase dure généralement deux à trois semaines mais représente un investissement indispensable. Une cartographie précise évite 80% des problèmes techniques et réglementaires qui surviennent lors de la migration effective.
Phase 2 - Migration progressive par composants
La migration doit se dérouler par couches successives. Cette approche progressive réduit nettement les risques et offre des points de contrôle réguliers. Elle permet surtout d’éviter les bascules “big bang”, presque toujours sources d’incidents majeurs.
Les quatre premières semaines sont entièrement consacrées aux données. Les bases sont migrées en réplication maître-esclave, ce qui permet de valider les performances de synchronisation en conditions réelles. Les procédures de sauvegarde et de restauration sont testées sur des jeux de données complets, et un retour en arrière reste possible à tout moment. C’est une phase très technique, mais essentielle pour sécuriser la suite.
Les semaines cinq à huit se concentrent sur les modèles IA. Les LLM, pipelines RAG ou modèles propriétaires sont déployés sur la nouvelle infrastructure et soumis à des tests de montée en charge progressifs : 10 % du trafic, puis 50 %, avant de basculer complètement. Les performances avant/après migration sont comparées avec précision, et les optimisations sont apportées au fil des observations. Cette séquence permet de valider que l’IA continue de répondre vite et de manière stable, sans dégrader l’expérience utilisateur.
Les quatre dernières semaines concernent les interfaces et l’orchestration. Les APIs et services web migrent à leur tour, accompagnés de tests utilisateurs menés sur des panels restreints. Un monitoring avancé surveille en continu les temps de réponse pour détecter immédiatement toute régression. En parallèle, les équipes support sont formées aux nouveaux outils et aux nouvelles procédures, afin d’assurer une transition propre côté exploitation.
La gestion des environnements suit une trajectoire volontairement graduelle : développement en premier, pour familiariser les équipes ; staging ensuite, en miroir exact de la production ; puis bascule finale en production, par segments utilisateurs, avec un rollback possible à chaque étape.
Au total, cette méthode étalée sur environ trois mois réduit drastiquement les risques opérationnels. Elle permet d’ajuster la stratégie en temps réel, selon les retours et les comportements observés, tout en garantissant une continuité de service irréprochable pour les utilisateurs finaux.
Conclusion : l'hébergement IA français, un atout concurrentiel
L'hébergement d'un SaaS IA en France n'est plus une question technique insoluble mais un avantage concurrentiel à saisir. Les solutions existent, les performances sont au rendez-vous, et les coûts restent maîtrisables avec la bonne approche méthodologique.
Les erreurs coûteuses se concentrent généralement sur quelques points critiques :
Sous-estimer l'impact organisationnel : prévoir 20% de temps supplémentaire les premiers mois
Négliger les tests de charge : les performances en dev ne reflètent jamais la production
Oublier la réversibilité : toujours garder une voie de retour possible
Ignorer les coûts de formation : budget 5-10k€ par développeur senior pour la montée en compétence
Avec une approche progressive, une expertise technique solide, et un accompagnement méthodologique adapté, la migration vers un hébergement IA français devient un projet maîtrisé qui renforce votre positionnement concurrentiel. L'investissement se rentabilise rapidement grâce à la confiance renforcée des clients européens et la sécurisation réglementaire à long terme.