Comparatif LLM 2026 : quel modèle choisir pour votre SaaS
36 min de lecture
Mis à jour le
1. Quel LLM choisir en 2026 ? Notre classement express
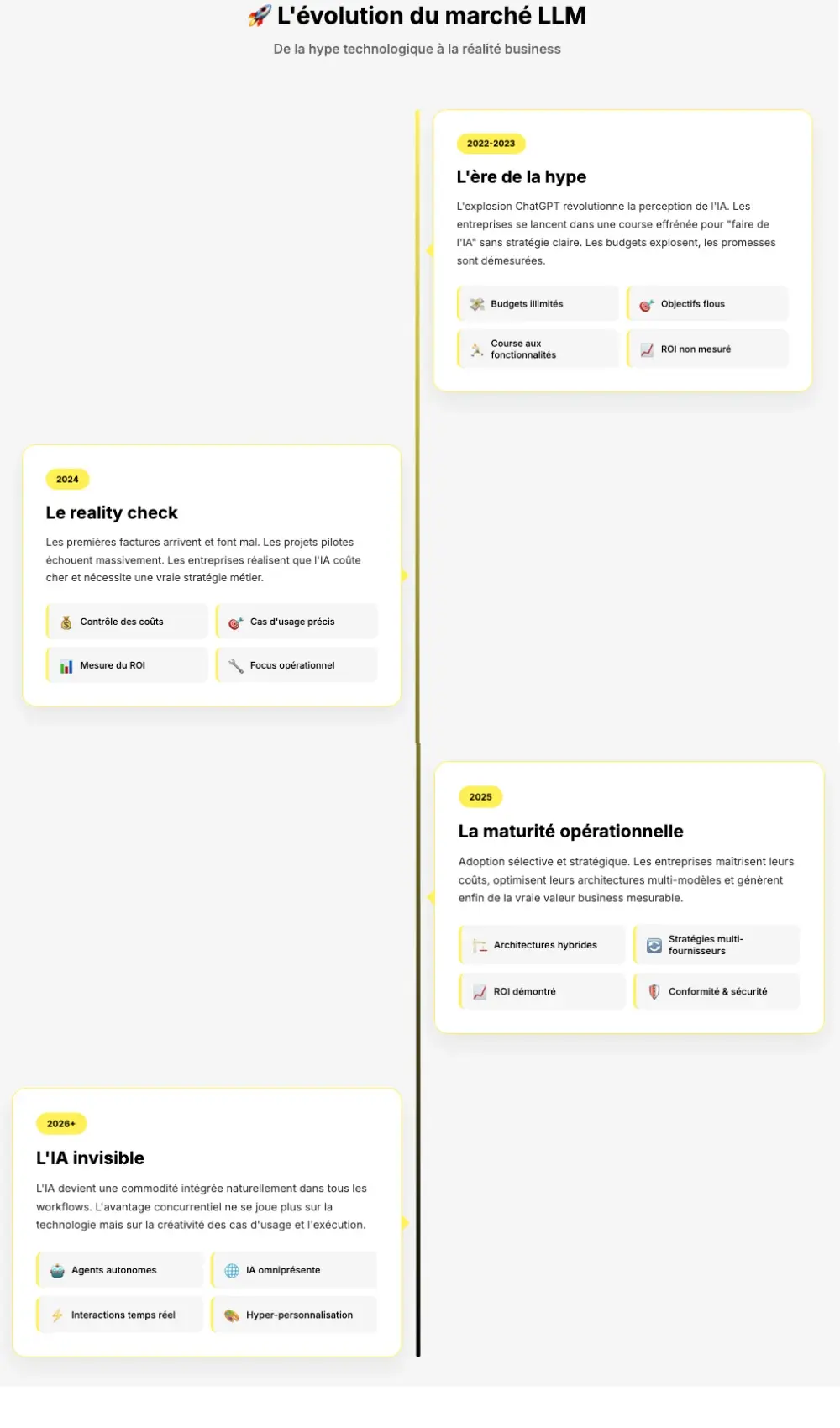
Allons droit au but. Si vous n’avez que trente secondes, voici notre classement des meilleurs LLM en 2026, par cas d’usage.
Pour lancer un MVP rapidement, Gemini 3.1 Pro (sorti le 19 février 2026) offre un excellent compromis entre puissance et coût. Il double les performances de raisonnement de Gemini 3 Pro et se hisse au 2e rang du classement Chatbot Arena (ELO 1500). C’est un modèle extrêmement attractif pour démarrer avec des performances de pointe sans plomber votre budget. À ses côtés, GPT-5.4 (sorti le 5 mars 2026) prend la relève de GPT-5.2 avec une fenêtre de contexte d’1 million de tokens, des niveaux de raisonnement configurables et un nouveau système Computer Use : stable, complet, et surtout, l’API OpenAI demeure une référence absolue de simplicité. Si vous cherchez la tranquillité pour valider votre idée, c’est le choix évident.
Pour le meilleur rapport qualité/prix global en production, Gemini 3 Flash (0,50 $ / 3 $ par million de tokens) ou Claude Sonnet 4.6 sont des choix redoutables. Encore mieux : le tout nouveau Gemini 3.1 Flash-Lite (mars 2026, 0,25 $ / 1,50 $ par million de tokens) écrase les prix pour les workloads à haut volume. Dans plus de 90 % des tâches généralistes rencontrées dans un SaaS, ces modèles délivrent une qualité proche des modèles premium pour un coût bien plus raisonnable. Et pour les budgets serrés, DeepSeek V3.2 offre des performances de niveau frontier à un prix défiant toute concurrence (0,14 $ en input).
Si vous recherchez une qualité premium sans compromis et que le budget est secondaire, Claude Opus 4.8 d’Anthropic se détache du lot. Sorti fin mai 2026, il succède à Opus 4.6 (février 2026) en améliorant les performances sur tous les benchmarks tout en conservant le même tarif. Avec une fenêtre de contexte de 1M de tokens, des capacités agentiques avancées (dont les “agent teams” et un nouveau système “dynamic workflow”) et un score de 65,4 % sur Terminal-Bench 2.0, c’est le choix premium par excellence. Mais cette excellence a un prix, et il est élevé.
En matière de facilité d’intégration, OpenAI (via GPT-5.4 et ses variantes) reste indétrônable. Aucun acteur ne rivalise aujourd’hui sur la qualité de la documentation, la simplicité des SDK et l’écosystème de développeurs. Si votre objectif est d’aller vite, sans friction, c’est un choix quasi incontournable.
Enfin, pour ceux qui misent sur l’open source et la souveraineté, l’écosystème a franchi un cap décisif. Mistral Large 3 (675B paramètres, Apache 2.0), Llama 4 (avec ses 10M de tokens de contexte), Qwen 3.7 Max (lancé mai 2026, classé 5e sur l’Artificial Analysis Intelligence Index v4.0), GLM-5.1 (744B paramètres, entraîné sur puces Huawei Ascend, licence MIT, avril 2026, 58,4 % sur SWE-bench Pro) ou Kimi K2.5 (1T paramètres, swarm de 100 agents) rivalisent désormais avec les modèles commerciaux sur de nombreuses tâches, y compris le tool calling, la génération de code et les agents spécialisés. L’écart avec les modèles propriétaires ne se mesure plus qu’en quelques points de qualité. Et surtout, leur coût peut être dérisoire comparé aux géants du marché.
→ Tendance forte : Les acteurs asiatiques dominent désormais l’open source. DeepSeek (V4 sorti avril 2026), Qwen (Alibaba, 3.7 Max en mai 2026), Zhipu AI (GLM-5.1 en avril 2026) et Moonshot AI (Kimi) publient des modèles à un rythme effréné, souvent à des coûts imbattables. Leur impact en entreprise européenne grandit, surtout pour des architectures multi-LLM où ils excellent en tant que modèles spécialisés. Côté US, xAI (Elon Musk) s’impose avec Grok 4.20, qui atteint le top 4 du Chatbot Arena (ELO ~1493 en avril 2026) grâce à une architecture multi-agents intégrée et une fenêtre de contexte de 2M de tokens.
L’architecture Mixture-of-Experts (MoE) s’est imposée comme le standard : des paramètres totaux massifs (675B à 1T) avec des paramètres actifs modestes (17B-41B), permettant des performances élevées avec une inférence efficiente. Côté Europe, Mistral Large 3 porte le drapeau, et des initiatives comme EuroLLM-22B (entraîné sur MareNostrum 5), OpenEuroLLM (premier modèle 8B attendu mi-2026) et SOOFI (Deutsche Telekom, opérationnel depuis mars 2026 avec ~130 systèmes DGX B200) concrétisent la souveraineté européenne en IA.
Au-delà du modèle seul, il faut évaluer l’écosystème autour : outils de développement, SDK, MCP (Model Context Protocol), désormais géré par l’Agentic AI Foundation (Linux Foundation), co-fondée par Anthropic, Block et OpenAI, avec 97M+ de téléchargements mensuels des SDK. Enfin, arbitrez aussi le choix local (Europe) vs. global selon votre sensibilité aux données, à la réglementation ou à la souveraineté.
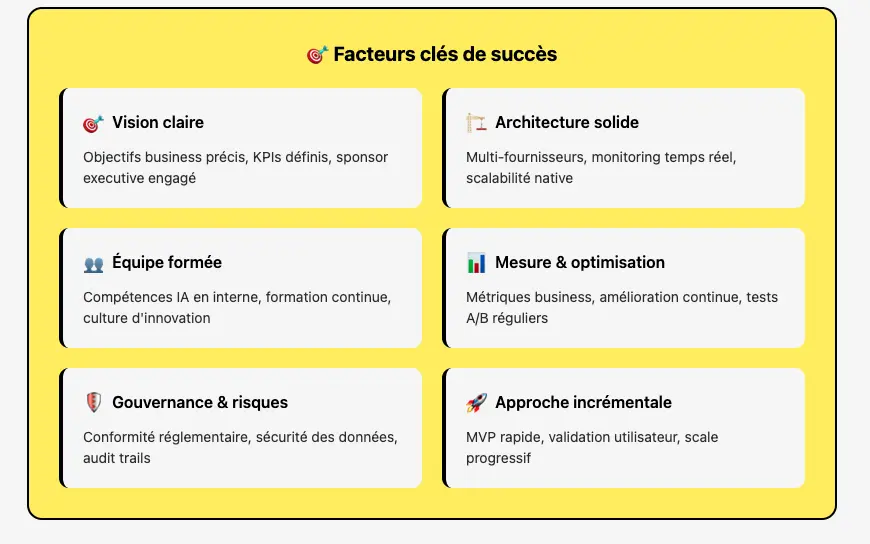
Notre conseil : Avant même de vous lancer, gravez ces trois leçons dans le marbre. D’abord, testez toujours votre cas d’usage avec un modèle State of the Art (SOTA) comme Claude Opus 4.6, Gemini 3.1 Pro ou GPT-5.4 pour mesurer à quoi ressemble l’excellence et disposer d’un benchmark solide. Ensuite, pensez multi-modèles dès le premier jour. Votre architecture doit être agnostique et capable de basculer d’un fournisseur à un autre en cas de panne ou de hausse tarifaire. Enfin, méfiez-vous des coûts et des pannes : la volatilité des tarifs est bien réelle et même les géants du marché subissent des indisponibilités parfois longues. Votre architecture doit être résiliente si vous ne voulez pas que votre produit s’arrête du jour au lendemain.
📊 Comparatif Express des LLM 2026
| Modèle | Coût (USD / 1M tokens in/out) | Points forts | Positionnement |
|---|---|---|---|
| Claude Opus 4.8 | 5 $ / 25 $ | Top mondial, contexte 1M, agent teams, dynamic workflow | Champion absolu code et reasoning |
| Gemini 3.1 Pro | 2 $ / 12 $ | Top #2 mondial (1500 ELO), raisonnement 2x vs 3 Pro, 1M contexte | Nouveau flagship Google (fév. 2026) |
| GPT-5.4 | 2,50 $ / 15 $ | 1M contexte, Computer Use, reasoning configurable | Nouveau flagship OpenAI (mars 2026) |
| GPT-5.2 | 1,75 $ / 14 $ | Multi-modalité avancée, caching 90%, stable | Flagship OpenAI gen. précédente |
| Claude Sonnet 4.6 | 3 $ / 15 $ | Performances proches d’Opus 4.5 à coût réduit | Sweet spot qualité/prix |
| Gemini 3 Pro | 2 $ / 12 $ | ELO 1485, 1M contexte, multimodal | Flagship Google (gen. précédente) |
| Gemini 3.1 Flash-Lite | 0,25 $ / 1,50 $ | Ultra-rapide, le moins cher de la gamme Gemini 3 | Workloads haut volume (mars 2026) |
| Gemini 3 Flash | 0,50 $ / 3 $ | Rapide, abordable, dépasse Gemini 2.5 Pro | Excellent rapport qualité/prix |
| DeepSeek V4 Pro | 1,74 $ / 3,48 $ | 1.6T params (49B actifs), 27% moins de compute que V3.2, multimodal | Nouveau flagship (avril 2026) |
| DeepSeek V4 Flash | 0,14 $ / 0,28 $ | 284B params (13B actifs), niveau frontier, prix imbattable | Challenger prix le plus agressif |
| GLM-5.1 | 1 $ / 3,20 $ | 744B params, MIT, 58,4% SWE-bench Pro, exécution autonome 8h | Open source chinois frontier (avril 2026) |
| Mistral Large 3 | 2 $ / 6 $ | 675B params, Apache 2.0, souveraineté européenne | Champion open source européen |
| Llama 4 Maverick | ~0,50 $ / ~0,77 $ | 400B params MoE, multimodal natif, open-weight | Alternative open source Meta |
| Qwen 3.7 Max | Variable (low-cost, open) | Top 5 Artificial Analysis Index v4.0, multimodal, code agentique | Open source flagship Alibaba (mai 2026) |
| Kimi K2.5 | Variable (low-cost, open) | 1T params, swarm 100 agents, vision+code | Open source agentique Moonshot AI |
2. La vision produit : Le vrai point de départ
Le choix d’un LLM n’est pas une décision technique. C’est une décision produit. Avant de vous noyer dans les comparatifs et les benchmarks, posez-vous d’abord cette question essentielle : “Quel problème précis suis-je en train de résoudre ?”
Trop d’entrepreneurs se lancent dans l’IA sans objectif clair, simplement parce qu’ils veulent “faire quelque chose avec l’IA.” Or, cela n’a jamais suffi à bâtir un produit viable. Si votre seul plan est d’intégrer un chatbot à votre SaaS sans savoir ce qu’il doit accomplir, votre projet court droit à l’échec. Ce qui compte, c’est d’identifier un besoin métier précis : quel processus souhaitez-vous automatiser ? Quelle expérience utilisateur voulez-vous améliorer ? Comment allez-vous mesurer le succès ?
Checklist stratégique :
-
Pourquoi utiliser un LLM dans mon produit SaaS ?
-
Quel problème métier précis est-ce que je résous ?
-
Mon produit serait-il toujours viable sans LLM ?
-
Le LLM crée-t-il de la valeur par :
-
Gain de temps
-
Personnalisation
-
Automatisation
-
Insight business
-
-
Existe-t-il un “Why LLM” unique justifiant un coût supplémentaire ou un avantage concurrentiel ?
-
Mon LLM sera-t-il intégré dans :
-
des fonctionnalités ponctuelles (Product features)
-
ou dans le cœur du produit (Core product) ?
-
-
Ai-je prévu un arbitrage local (modèles européens) ou global (US, Asie) selon la sensibilité de mes données ?
Pour savoir si un LLM est pertinent dans votre cas, la méthode la plus sûre reste la construction d’un jeu de tests structuré. Avant même de lancer la moindre requête API, prenez un exemple réel de donnée que votre produit devra traiter : un email, un document technique, une transcription d’appel. Décrivez ensuite très précisément le traitement attendu : doit-il extraire des informations clés ? Classer un texte ? Résumer un contenu ? Et enfin, rédigez vous-même la réponse idéale. Ce petit fichier Excel ou Notion devient alors votre boussole pour comparer objectivement les modèles, plutôt que de vous fier à des promesses marketing ou à des benchmarks génériques.
Côté coûts, c’est le casse-tête absolu de tout fondateur de SaaS. Tant que votre produit n’est pas développé, vous avez une vision quasi nulle du nombre de tokens que vous allez consommer. Une simple fonctionnalité de génération de proposition commerciale peut exploser votre budget si vos prompts sont trop longs ou si votre agent multiplie les appels à différents tools. Le business plan doit intégrer cette incertitude fondamentale. Un conseil : acceptez qu’au début, vous ne pourrez travailler que sur des ordres de grandeur approximatifs. Et ajustez ensuite au réel, une fois les premiers tests effectués.
Les paradoxes à anticiper pour éviter les désillusions
L’instinct pousse souvent à choisir le modèle le plus intelligent. En réalité, c’est parfois une erreur.
Premier paradoxe : celui de la sévérité. Prenons un outil de scoring de CV. Un modèle très puissant comme Claude Opus 4.8 peut devenir tellement strict qu’il rejette 99 % des candidatures, s’arrêtant sur des détails insignifiants qu’un humain écarterait.
Et ce n’est pas tout : ces modèles ultra-performants sont aussi plus opaques. L’effet boîte noire rend les décisions difficiles à expliquer, les biais sont plus subtils mais bien réels, et les contraintes de confidentialité peuvent vite devenir bloquantes.
À l’inverse, un modèle “moyen” se montrera parfois plus pragmatique, et surtout, plus rentable.
Deuxième piège : le syndrome du bon élève. Lorsqu’un LLM manque d’informations, il n’admet presque jamais qu’il ne sait pas. Au contraire, il hallucine et fabrique une réponse parfaitement structurée, parfois brillante… mais totalement inventée.
C’est ce qui le rend si dangereux : il paraît sûr de lui, même quand il a tort.
Ce qu’il faut retenir : Le choix d’un LLM doit partir du produit, pas de la hype technologique. Ce n’est qu’en connaissant parfaitement vos cas d’usage et vos contraintes métier que vous éviterez les mauvaises surprises. Et surtout, n’oubliez jamais qu’un modèle moins puissant peut souvent se révéler plus utile, plus stable et beaucoup moins coûteux.
3. Les critères métier qui changent la donne
On pourrait croire que choisir un LLM se résume à comparer des benchmarks ou des prix au million de tokens. Mais pour un produit SaaS, c’est loin d’être suffisant. Trois critères opérationnels font toute la différence entre un projet qui fonctionne et un projet qui explose en vol.
L’écosystème : la clé pour aller vite
Un LLM, aussi brillant soit-il, ne sert à rien sans un bon outillage autour. L’écosystème est roi. Aujourd’hui, OpenAI reste le champion incontesté sur ce terrain. Leur API est d’une clarté redoutable, les SDK abondent, la documentation est limpide, et la communauté est gigantesque. Si votre objectif est de démarrer vite, c’est l’option la plus rassurante.
Mais l’écosystème moderne ne se limite plus à un seul fournisseur. Les stacks techniques s’enrichissent de nouveaux outils qui changent radicalement la donne. Vercel AI SDK (version 6 stable, version 7 en canary), par exemple, s’impose comme un indispensable pour gérer une architecture multi-fournisseurs avec plus de 20 millions de téléchargements mensuels. Il offre désormais un ToolLoopAgent natif, un support complet de MCP, un système d’approbation d’outils (human-in-the-loop) et des DevTools intégrés pour le debug. Il normalise les appels API et simplifie l’orchestration et le fallback entre OpenAI, Google, Anthropic et les modèles open source.
Pour piloter vos modèles, un outil comme Langfuse devient vite incontournable. C’est votre tour de contrôle : tracing ultra-détaillé de chaque requête, évaluation des performances (y compris au niveau de chaque opération individuelle), versioning de datasets, CLI pour agents, et constitution d’une base de logs exhaustive. Mieux encore, c’est une condition quasi obligatoire pour se préparer aux exigences de l’IA Act, dont un accord provisoire a été trouvé le 7 mai 2026 : les obligations pour les systèmes à haut risque Annexe III sont reportées au 2 décembre 2027 (au lieu du 2 août 2026), et celles pour les systèmes Annexe I au 2 août 2028. L’adoption formelle par le Parlement et le Conseil est attendue en juillet 2026.
Enfin, si vous souhaitez évaluer objectivement vos sorties, Langfuse est l’allié idéal. Il permet de mettre en place des systèmes de “LLM as a Judge”, où un LLM vient évaluer un autre LLM sur vos cas d’usage réels. C’est la garantie d’une mesure objective de qualité, plutôt que de se fier à son intuition ou à quelques tests anecdotiques.
Le coût réel : une équation à plusieurs inconnues
Le prix affiché par million de tokens n’est que le début de l’histoire. Le coût réel de votre IA dépend de l’architecture de votre produit et de la façon dont vos utilisateurs l’utilisent. Pour anticiper concrètement votre budget, testez plusieurs scénarios dans notre simulateur de coûts IA.
Les vrais multiplicateurs de coût sont :
-
Le nombre d’outils par requête : un agent qui interroge CRM + email + calendrier coûte 5x plus qu’un simple chatbot
-
La longueur du contexte : maintenir une conversation de 10 000 tokens coûte plus cher qu’un échange ponctuel
-
Les tokens de sortie : souvent 3-4x plus chers que les tokens d’entrée
-
La fréquence d’usage : un utilisateur power peut générer 50x plus de requêtes qu’un utilisateur occasionnel

Testez différents scénarios pour anticiper vos coûts réels, éviter les mauvaises surprises… et choisir un plan adapté à vos ambitions.
La fiabilité et la stabilité : votre police d’assurance
Même les géants trébuchent. Les pannes de plusieurs heures chez OpenAI ou Anthropic ne sont pas rares. Et il y a un autre facteur souvent sous-estimé : la variabilité de qualité. Un même modèle peut produire un contenu impeccable un jour, et devenir beaucoup moins fiable le lendemain, sans explication apparente.
Si votre service SaaS dépend intégralement d’un seul fournisseur, une panne chez lui signifie que votre service est tout simplement à l’arrêt. Et si vous êtes en pleine phase de croissance, c’est un risque que vous ne pouvez pas vous permettre.
La seule parade, c’est une architecture flexible, pensée pour intégrer un fallback multi-fournisseurs. Si le modèle A ne répond pas, votre système doit automatiquement basculer vers le modèle B. Cette logique de bascule, couplée à des mécanismes de retry intelligent, est aujourd’hui la seule assurance sérieuse contre les aléas du cloud.
💡 En résumé : Choisir un LLM, ce n’est pas simplement comparer des tarifs. C’est construire un produit robuste, scalable et résilient. Un modèle peut être excellent sur le papier et ruiner votre business s’il est mal intégré, trop cher à l’usage ou trop instable. La vraie force d’un SaaS en 2026, c’est une architecture multi-modèles, pilotée et monitorée avec précision. Sans cela, même le meilleur modèle du marché peut devenir votre pire ennemi.
4. Architectures avancées : penser comme en 2026
Croire qu’un seul LLM peut tout faire est une vision déjà dépassée. C’est comme espérer qu’un seul artisan puisse construire toute votre maison, de la charpente aux finitions. Votre produit SaaS est un ensemble complexe de tâches très différentes : extraction d’informations, rédaction, classement, compréhension contextuelle… Il n’y a pas un seul modèle parfait pour tout.
La clé en 2026, c’est le multi-modèles.
Pourquoi miser sur plusieurs modèles ?
Deux raisons majeures expliquent ce choix stratégique :
-
Optimisation des coûts. Pourquoi payer GPT-5.2 plusieurs dollars le million de tokens pour extraire du texte d’un PDF ? Un modèle spécialisé comme Mistral OCR fera le travail 150 fois moins cher et souvent mieux.
-
Optimisation des performances. Chaque modèle a ses points forts. Claude Opus 4.6 excelle en raisonnement complexe, Gemini 3 Flash est rapide et efficace sur des tâches généralistes, Mistral OCR est imbattable pour l’extraction de texte.
Exemple terrain :
Vous devez traiter une facture PDF. Utiliser GPT-5.2 serait un gaspillage monumental. Un modèle OCR spécialisé vous coûtera beaucoup moins cher et offrira un résultat plus précis. Réservez vos LLM premium aux tâches où leur intelligence fait vraiment la différence.
L’orchestration multi-LLM : la chaîne de montage intellectuelle
En 2026, construire un SaaS, c’est concevoir une chaîne de montage intellectuelle, où chaque étape est confiée au modèle le plus adapté.
Une tâche complexe n’est pas un bloc monolithique. Elle peut souvent se découper ainsi :
-
Raisonnement. Par exemple, Claude Opus 4.8, Gemini 3.1 Pro ou GPT-5.4 pour analyser une requête complexe et déterminer un plan d’action.
-
Exécution / Recherche. Gemini 3 Flash ou DeepSeek V4 Flash peuvent collecter des données, extraire des informations ou synthétiser des contenus rapidement et à moindre coût.
-
Rédaction finale. Claude Sonnet 4.6 peut être utilisé pour produire une réponse soignée avec un style impeccable.
Les frameworks modernes, comme LangGraph (version 1.0 GA depuis fin 2025, avec une mise à jour majeure en mai 2026 ajoutant timeouts par nœud, gestion d’erreurs avancée et DeltaChannel pour l’optimisation mémoire), sont spécifiquement conçus pour orchestrer ces chaînes de modèles. Ils permettent de combiner plusieurs LLM dans un seul workflow cohérent, avec des mécanismes sophistiqués de fallback, de réévaluation, d’auto-critique entre modèles, et désormais de mémoire cross-thread avec recherche sémantique. Le protocole MCP (Model Context Protocol), désormais géré par l’Agentic AI Foundation (Linux Foundation), co-fondée par Anthropic, Block et OpenAI avec le soutien de Google, Microsoft et AWS, standardise les connexions entre vos agents et vos outils métier. Avec 97 millions de téléchargements mensuels des SDK Python et TypeScript, MCP s’impose comme le standard de facto pour l’IA agentique.
Penser architecture flexible dès le jour 1
Ce n’est pas un luxe. C’est une nécessité. Dans un environnement où :
-
les tarifs peuvent fluctuer brutalement,
-
les API subissent parfois des pannes,
-
et la souveraineté devient un enjeu stratégique,
il est vital que votre SaaS ne repose jamais sur un seul modèle ni un seul fournisseur. Vous devez pouvoir :
✅ Switcher facilement vers un autre LLM si un modèle devient trop cher, indisponible, ou non conforme aux nouvelles régulations.
✅ Mixer plusieurs modèles dans un même processus pour réduire vos coûts et augmenter la qualité de vos sorties.
✅ Garantir la continuité de service, même en cas d’incident technique chez un provider.
5. Cas d’usage détaillés : La réalité du terrain
Choisir un LLM, ce n’est pas une affaire de simples benchmarks théoriques. La vraie différence se joue dans la réalité des cas d’usage. Voici trois exemples concrets qui montrent à quel point les choix techniques doivent s’adapter à la nature précise de la tâche.
Traitement de documents : Chaque étape son outil
Le traitement de documents implique souvent plusieurs étapes distinctes qu’il faut bien distinguer :
1. Extraction de texte : selon le type de document, il peut s’agir :
-
d’une ingestion sans IA (fichiers structurés comme PDF texte, Word, PowerPoint, Excel)
-
ou d’un passage par OCR (documents scannés ou images)
-
ou des deux combinés
2. L’analyse : comprendre, interpréter et extraire des informations du contenu textuel
Beaucoup d’équipes SaaS pensent qu’il suffit d’envoyer directement leurs documents à un modèle généraliste comme GPT-5.4 ou Claude Opus 4.8. Parce qu’ils sont puissants, ils devraient savoir tout faire, non ?
En réalité, c’est souvent une grosse erreur. Ces modèles généralistes sont surdimensionnés pour les tâches purement techniques comme l’OCR ou l’ingestion. Ils coûtent cher, consomment des tokens à foison et ne sont pas forcément plus précis qu’un outil spécialisé.
Scoring automatique : L’illusion de la boîte noire
Le scoring automatique (évaluation de CV, leads commerciaux, propositions) est un piège classique. L’intuition pousse à demander directement au LLM : “Note ce CV de 1 à 10”. C’est tentant, mais c’est rarement la bonne approche.
Pourquoi les LLMs ne sont pas faits pour le scoring direct :
-
Effet boîte noire : impossible de comprendre pourquoi telle note a été attribuée
-
Biais imprévisibles : le modèle peut privilégier certains profils sans raison transparente
-
Variabilité : le même document peut recevoir des notes différentes selon le contexte
-
Responsabilité légale : difficile de justifier une décision d’embauche basée sur un score “magique”
L’approche qui fonctionne : utilisez le LLM pour générer les critères et extraire les données, puis implémentez un algorithme de scoring transparent :
-
Le LLM extrait : compétences, expérience, formations, etc.
-
Le LLM suggère : critères de notation adaptés au poste
-
L’algorithme score : selon des règles métier claires et auditables
-
Le LLM explique : pourquoi ce score a été attribué
Cette approche hybride combine l’intelligence du LLM avec la transparence d’un système de règles classique.
🗣️ IA vocale : Une révolution UX… mais pas sans coût
L’IA vocale a franchi un cap décisif. L’API Realtime d’OpenAI est désormais en disponibilité générale avec le modèle gpt-realtime, capable de gérer des conversations voix-à-voix avec support d’images, de serveurs MCP et même d’appels téléphoniques via SIP. Les prix ont baissé de 20 % par rapport à la version preview (32 $/M tokens audio en entrée, 64 $/M en sortie). Google a renforcé Gemini Live en acquérant l’équipe de Hume AI (spécialiste de la voix émotionnelle). Il est désormais possible d’intégrer des conversations vocales avec une IA capable de comprendre la voix, de répondre intelligemment et de rebondir avec une latence très faible.
C’est une révolution, surtout dans des contextes comme le support client, la vente assistée ou la navigation dans des applications complexes. Mais il faut aussi regarder la réalité des coûts.
-
Une conversation vocale implique généralement plusieurs modèles : un pour convertir la voix en texte (STT), un LLM pour traiter la requête, puis un autre pour retranscrire la réponse en voix (TTS).
-
Les modèles speech-to-speech comme gpt-realtime proposent une gestion unifiée de bout en bout, avec une latence minimale, mais ce confort a un prix : comptez environ 32 $ / 1M tokens audio en entrée et 64 $ en sortie, soit environ 0,04 $/min en pratique grâce au prompt caching implicite. C’est souvent 3 à 4 fois plus cher qu’une architecture orchestrée STT + LLM + TTS.
-
Chaque étape génère des coûts supplémentaires et des appels API multiples.
-
Le résultat : une facture qui peut vite exploser, même sur des volumes modestes. Le marché de la voice AI a dépassé 22 milliards $ en 2026 et est projeté à 47,5 milliards $ d’ici 2034, avec des tarifs allant de 0,05 à 0,35 $/min selon les plateformes et les composants (STT à 0,003-0,008 $/min, TTS à 0,03-0,10 $/min pour les voix ultra-réalistes, plus l’inférence LLM).
Pour intégrer la voix dans votre SaaS sans réinventer la roue, des SDK open source comme MicDrop simplifient considérablement le travail. MicDrop gère le pipeline complet (capture audio, détection de voix, STT, orchestration LLM, TTS) en quelques lignes de code, avec une architecture modulaire qui vous laisse choisir vos providers (OpenAI, ElevenLabs, Mistral, Gladia…). Gratuit et sous licence MIT, il suit un modèle “bring your own API keys” qui vous permet de garder le contrôle total sur vos coûts et vos fournisseurs.
💡 Astuce : même si la techno est prête, dimensionnez toujours vos coûts. Testez vos cas d’usage réels avant d’annoncer une expérience vocale “illimitée” dans votre SaaS.
✔️ À retenir sur les cas d’usage
✅ Les modèles généralistes ne sont pas universels. Utilisez-les là où leur intelligence est nécessaire, mais pas pour des tâches techniques simples.
✅ Pour des tâches nécessitant de la tolérance (scoring, rédaction commerciale), un modèle moins puissant peut parfois offrir de meilleurs résultats métier.
✅ L’IA vocale est prête pour la production, mais c’est un gouffre potentiel si elle n’est pas soigneusement budgétisée.
En résumé : Dans un SaaS, le bon LLM n’est jamais une réponse unique. Chaque tâche a son modèle idéal. Et c’est là que se joue la performance réelle de votre produit, bien plus que dans les benchmarks officiels.
6. Enjeux stratégiques et vision du marché
Derrière le choix d’un LLM se cachent des enjeux bien plus vastes que la simple performance technique. C’est une décision stratégique. Car le marché des IA génératives, en 2026, est en pleine mutation, porté par des forces économiques, géopolitiques et réglementaires qui rebattent totalement les cartes.
Souveraineté et dépendance : le vrai risque
S’appuyer uniquement sur des acteurs américains comme OpenAI ou Anthropic expose les entreprises européennes à un risque majeur de dépendance. Les tensions géopolitiques grandissantes et la pression réglementaire, notamment avec l’IA Act, créent une incertitude réelle sur la pérennité de certains services étrangers en Europe.
Aujourd’hui, de plus en plus d’entreprises françaises ou européennes affichent une préférence marquée pour des solutions locales ou open source, non seulement pour des raisons de conformité, mais aussi pour garantir que leurs données sensibles ne quittent pas le territoire.
➡ Lien souveraineté / offres locales :
Même si les modèles américains restent leaders, des acteurs européens ou open source comme Mistral Large 3 (675B paramètres, Apache 2.0) constituent désormais des options sérieuses. Les initiatives de souveraineté européenne progressent concrètement : OpenEuroLLM (consortium de 20 institutions coordonné par l’Université Charles de Prague, modèle 8B attendu été 2026, accès sécurisé aux supercalculateurs EuroHPC LUMI, Leonardo et MareNostrum), EuroLLM-22B (couvrant les 24 langues de l’UE, entraîné sur MareNostrum 5), et SOOFI (Deutsche Telekom, ~130 systèmes DGX B200 opérationnels depuis mars 2026, ciblant un LLM souverain de ~100B paramètres). L’écart de qualité avec les grands modèles globaux se réduit significativement, surtout sur des tâches spécialisées.
Ce qu’il faut retenir : même si les modèles américains restent leaders en termes de qualité, miser uniquement sur eux peut devenir une stratégie à haut risque. Une architecture flexible, capable de basculer sur des modèles européens ou open source, est votre meilleure assurance.
La convergence des modèles : la bataille des 95 %
Autre tendance forte : la convergence des modèles. Aujourd’hui, des modèles comme Gemini 3.1 Flash-Lite, Claude Sonnet 4.6, DeepSeek V3.2 et les variantes de GPT-5 couvrent déjà 90 à 95 % des usages courants dans un SaaS. Pour beaucoup de fonctionnalités – rédaction, résumé, classification – leurs performances se rapprochent de plus en plus. Le vrai différenciateur ne se trouve plus toujours dans le modèle lui-même, mais dans la manière de l’orchestrer, de le combiner avec d’autres modèles spécialisés et de l’intégrer intelligemment dans le produit.
En clair : la compétition ne se joue plus uniquement sur la puissance brute des LLM, mais sur la créativité des architectures qui les exploitent.
Les stratégies des providers : entre montée en gamme et segmentation
Les grands acteurs du marché n’avancent pas tous dans la même direction :
-
OpenAI poursuit une stratégie de montée en gamme avec GPT-5.4 (sorti le 5 mars 2026, intégrant les capacités de GPT-5.3-Codex) et a déposé son dossier S-1 de manière confidentielle auprès de la SEC le 22 mai 2026, visant une introduction en bourse au T4 2026 ou début 2027 avec une valorisation cible entre 852 milliards $ et 1 000 milliards $. L’entreprise a bouclé une méga-levée de 122 milliards $ en mars 2026 (Amazon 50B$, Nvidia 30B$, SoftBank 30B$, plus 3B$ d’investisseurs individuels), portant la valorisation post-money à 852 milliards $. Son chiffre d’affaires atteint 2 milliards $ par mois (soit ~24 milliards $ annualisés), avec le B2B représentant désormais 40 % du revenu. Leur objectif est clair : intégrer un maximum de fonctionnalités (agents, outils externes, recherche, vision, voix) pour justifier des abonnements toujours plus élevés et booster leur ARPU. Le risque, pour les clients, c’est de devenir captifs d’un écosystème de plus en plus coûteux.
-
Anthropic (Claude) monte en puissance dans le segment enterprise avec un chiffre d’affaires annualisé qui a explosé à 47 milliards $ fin mai 2026 (contre 9 milliards $ fin 2025). L’entreprise a bouclé une levée Series H de 65 milliards $ fin mai 2026 à une valorisation de 965 milliards $, menée par Altimeter Capital, Dragoneer, Greenoaks et Sequoia Capital. Plus de 1 000 clients dépensent désormais plus de 1 million $ par an sur Claude (doublé depuis avril 2026). Claude Opus 4.8, sorti fin mai 2026, succède à Opus 4.6 en améliorant tous les benchmarks. Claude Code génère à lui seul 2,5 milliards $ de revenus annualisés. Fort accent sur le code, les workflows techniques et les agents autonomes.
-
L’open source a franchi un cap décisif. L’architecture MoE (Mixture-of-Experts) permet désormais aux modèles open source comme Mistral Large 3, DeepSeek V4, Qwen 3.7 Max, GLM-5.1 ou Kimi K2.5 de rivaliser avec les modèles commerciaux sur la plupart des tâches. GLM-5.1 (avril 2026), entraîné entièrement sur puces Huawei Ascend sans dépendance à NVIDIA, atteint 58,4 % sur SWE-bench Pro et supporte jusqu’à 8 heures d’exécution autonome. DeepSeek V4 (avril 2026) introduit deux variantes : V4-Pro (1,6T paramètres, 49B actifs) et V4-Flash (284B, 13B actifs), avec une efficacité computationnelle améliorée de 73 % par rapport à V3.2 grâce à une attention sparse compressée. Côté Alibaba, Qwen 3.7 Max (mai 2026) se classe 5e sur l’Artificial Analysis Intelligence Index v4.0, devenant le modèle chinois le mieux classé à son lancement.
Le marché en mutation : une opportunité gigantesque
Toutes ces évolutions créent un terrain de jeu gigantesque pour les SaaS B2B. Les entreprises capables de s’emparer rapidement de ces nouvelles technologies, de bâtir des architectures multi-modèles intelligentes, et de maîtriser les enjeux de souveraineté et de conformité, disposent aujourd’hui d’un avantage concurrentiel colossal.
Ce qu’il faut garder en tête : la véritable innovation ne viendra plus seulement des modèles eux-mêmes. Elle viendra surtout de la capacité à construire des architectures créatives et hybrides, optimisées à la fois pour la performance, la souveraineté, le coût et la conformité.
💡 En résumé : En 2026, le choix d’un LLM est un acte stratégique. Il engage la souveraineté de vos données, votre capacité à pivoter face aux évolutions du marché, et votre solidité face aux exigences réglementaires. Miser sur un seul acteur, c’est prendre un risque. Miser sur une architecture flexible et multi-modèles, c’est investir dans la résilience et la compétitivité de votre produit.
7. Données factuelles : Les chiffres qui comptent
Au-delà des discours marketing et des impressions terrain, les chiffres restent la meilleure boussole pour choisir votre LLM. Voici un instantané des tarifs et caractéristiques des principaux modèles sur le marché début 2026. Attention : ces chiffres évoluent vite. Les prix que vous lisez aujourd’hui peuvent être divisés par deux – ou multipliés – d’ici quelques mois.
Les tendances à surveiller
-
Les prix chutent à un rythme effréné. Les coûts d’inférence baissent d’environ 10x par an à qualité équivalente. Gemini 3.1 Flash-Lite écrase les prix (0,25 $/M tokens en input), DeepSeek V4 Flash propose du frontier à 0,14 $/M tokens en input (avec 90 % de réduction via le cache), et tous les providers offrent désormais 50 % de réduction en batch et jusqu’à 90 % via le prompt caching.
-
Les coûts réels dépassent toujours le prix du token. Entre la longueur des prompts, les multi-tool calls et les éventuels agents, la facture finale peut être 5 à 20 fois supérieure au tarif affiché. L’écart de prix entre le modèle le moins cher (DeepSeek V4 Flash cache hit : 0,028 $/M) et le plus cher (Claude Opus 4.8 output : 25 $/M) est de près de 900x.
-
L’open source rivalise frontalement. DeepSeek V4, Mistral Large 3, Qwen 3.7 Max, GLM-5.1, Kimi K2.5 et Llama 4 proposent des performances comparables aux modèles commerciaux sur de nombreuses tâches. GLM-5.1 (avril 2026, licence MIT, entraîné sur puces Huawei Ascend) atteint 58,4 % sur SWE-bench Pro, surpassant GPT-5.4, Claude Opus 4.6 et Gemini 3.1 Pro. Mistral Small 4 (119B paramètres MoE, mars 2026, Apache 2.0) unifie raisonnement, multimodal et code agentique dans un seul modèle. L’écart ne se mesure plus qu’en quelques points de qualité.
⚠️ Les pièges des données chiffrées
Même si ces chiffres sont précieux, il faut savoir les manier avec précaution. Beaucoup de fondateurs SaaS tombent dans le piège du calcul simpliste : “mon modèle coûte 0,075 $ / 1M tokens, donc mon budget sera bas.” Faux. Dans la réalité, votre coût dépendra de :
-
La longueur des prompts.
-
Le volume de données contextuelles injectées dans chaque requête.
-
La taille des réponses générées.
-
Le nombre d’étapes dans vos workflows, surtout si vous utilisez des agents IA.
Un MVP peut coûter quelques dizaines d’euros par mois. Mais à l’échelle, un seul bug, une boucle infinie ou une attaque exploitant votre clé API peut transformer une facture de 10 € en 10 000 €. D’où la nécessité absolue de simuler vos scénarios et de poser des limites.
➡ Où trouver ces chiffres ?
-
Rapports publics des providers (OpenAI, Google, Anthropic, Mistral…)
-
Tests internes réalisés sur vos propres jeux de données
-
Benchmarks partagés sur GitHub ou publications spécialisées (Hugging Face, LLM Arena, etc.)
Attention aux benchmarks contaminés : le 23 février 2026, OpenAI a publié un rapport démontrant que les modèles frontier (GPT-5.2, Claude Opus 4.5, Gemini 3 Flash) reproduisaient les solutions SWE-bench Verified de mémoire, avec près de 60 % des problèmes échoués contenant des tests fondamentalement cassés. Les modèles affichant ~80 % sur Verified chutent à ~23 % sur le nouveau SWE-bench Pro (1 865 tâches sur 41 repos actifs en Python, Go, TypeScript et JavaScript, incluant des codebases propriétaires jamais publiées pour prévenir structurellement la contamination), qui s’impose comme le benchmark de remplacement. Privilégiez vos propres jeux de tests pour évaluer la qualité réelle.
Toujours recouper plusieurs sources : un seul benchmark ne suffit pas à refléter la réalité de votre produit.
💡 En résumé : Les chiffres sont indispensables pour comparer vos options, mais ils ne racontent jamais toute l’histoire. Le coût réel d’un LLM dépend toujours de votre cas d’usage et de votre architecture. Et en 2026, une veille constante des tarifs est plus stratégique que jamais.
8. Sécurité & coûts cachés : Les dangers invisibles
Si choisir un LLM se résumait à comparer des prix et des benchmarks, la vie serait simple. Mais dans la réalité, les coûts cachés et les risques de sécurité constituent une part énorme de l’équation. Beaucoup de fondateurs SaaS l’apprennent à leurs dépens, parfois avec des factures à cinq chiffres qui tombent du jour au lendemain.
Les boucles infinies : la bombe à retardement
Imaginez un agent IA mal codé, qui se met à appeler l’API en boucle parce qu’il attend une réponse spécifique qui ne vient jamais. En quelques minutes, il peut générer des millions de tokens consommés. Une facture de quelques euros peut grimper à plusieurs milliers en une seule nuit.
Bonne pratique : Ne mettez jamais la recharge automatique sur vos comptes LLM. Activez plutôt des alertes budgétaires progressives (50 %, 75 %, 90 %) et rechargez manuellement. C’est votre première ligne de défense.
Le vol de clés API : un fléau sous-estimé
Autre risque majeur : la fuite de clés API. Par exemple, Une clé poussée accidentellement dans un repo public sur GitHub est détectée en quelques secondes par des bots. Et aussitôt exploitée pour générer du trafic massif, à vos frais.
Les providers ont beau proposer des protections et des rotations de clés, il suffit d’une seule erreur humaine pour que votre compte cloud soit vidé.
Conseil : Générez une clé par projet et par environnement, stockez les dans des vaults sécurisés et auditez régulièrement vos dépôts publics.
Les variations de qualité : le syndrome du “même modèle, résultat différent”
Même à modèle identique, la qualité des réponses peut fluctuer d’un jour à l’autre. Le côté aléatoire inhérent au modèle (dépendant notamment de la température qu’on lui donne) ainsi que des changements internes chez les providers, peuvent impacter :
-
la rapidité des réponses,
-
la pertinence des outputs,
-
la tolérance aux prompts inhabituels.
💡 Cette variabilité peut ruiner un flux de travail qui semblait parfaitement stable quelques semaines plus tôt.
Ce qu’il faut retenir
En 2026, la sécurité et le contrôle budgétaire sont aussi stratégiques que la qualité des modèles. Un bon SaaS IA, ce n’est pas juste du code. C’est avant tout une architecture sécurisée, vigilante et capable de détecter les anomalies avant qu’elles ne fassent exploser vos coûts.
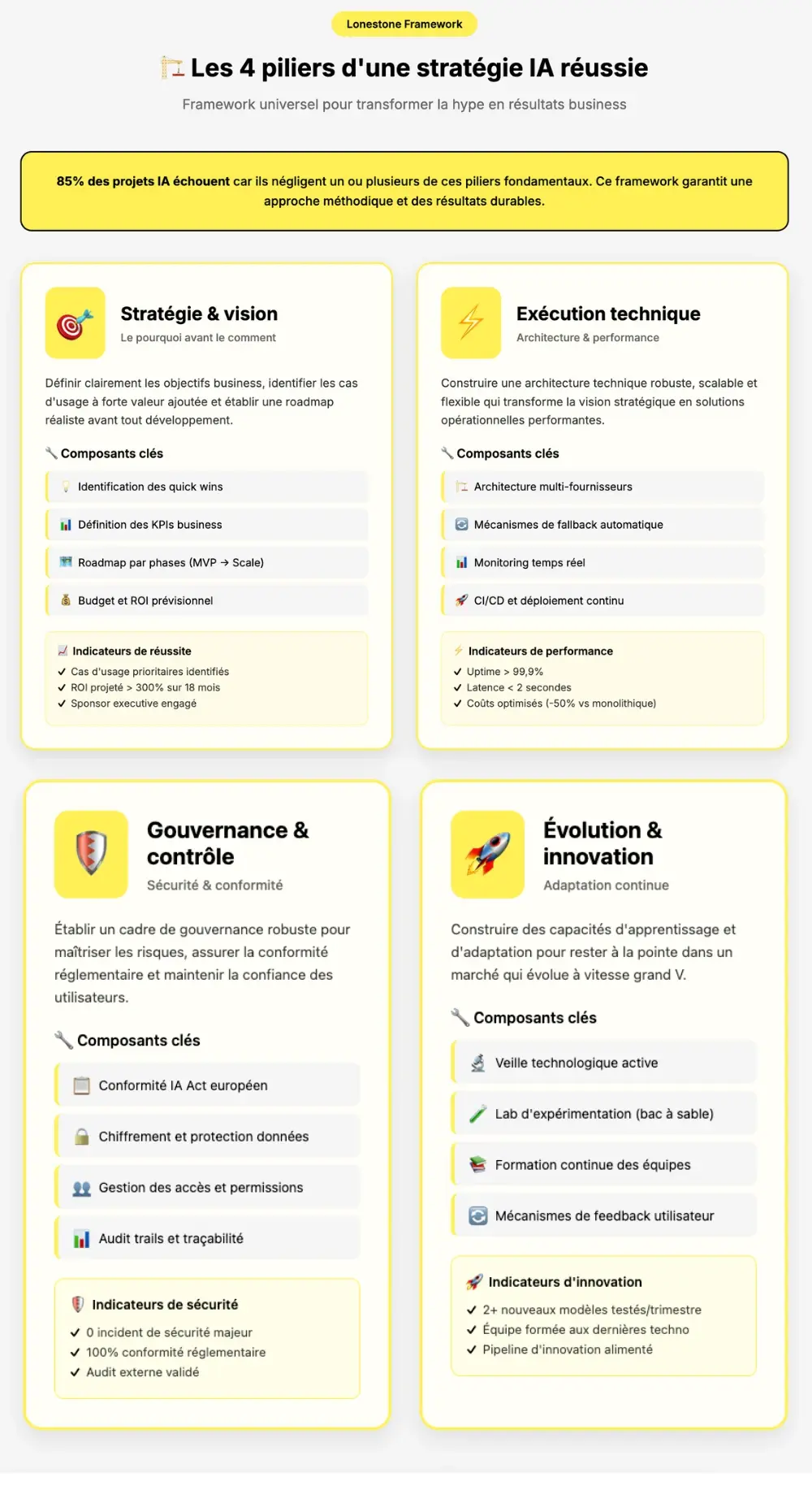
9. Différenciation Lonestone : Ce qui change vraiment la donne
Chez Lonestone, nous concevons des outils métier et des SaaS augmentés par l’IA — avec une attention portée à l’utilité, à la robustesse et à la performance réelle en production.
Dans la jungle des comparatifs LLM, beaucoup se ressemblent. Benchmarks académiques, vidéos YouTube, blogs de passionnés… tous affichent des tableaux chiffrés et des courbes. Mais la vraie vie d’un SaaS, elle, est beaucoup plus complexe.
Chez Lonestone, notre différence se joue sur trois piliers :
-
Des retours terrain réels. Nous parlons de projets concrets, pas de théories. Nous avons intégré ces modèles dans des produits vivants, confrontés à des utilisateurs, à des bugs et à des enjeux business.
-
La réalité des coûts. Nous savons ce que coûte vraiment un LLM en production, au-delà des prix marketing affichés. Et nous partageons ces chiffres pour aider nos clients à éviter les pièges.
-
Des insights exclusifs. Nous alertons sur des paradoxes que personne n’évoque : comme le fait qu’un modèle trop intelligent peut parfois nuire à votre business, ou qu’un modèle “moyen” peut être plus efficace pour certaines tâches.
Notre conviction : le vrai avantage compétitif en 2026 ne se trouve plus uniquement dans le modèle que vous choisissez. Il se trouve dans la manière dont vous orchestrez vos modèles, gérez vos coûts et construisez une architecture résiliente. C’est cette expertise-là que nous mettons au service de nos clients.
En conclusion : Choisir son LLM en 2026, ce n’est plus simplement cocher une case sur un tableau comparatif. C’est un acte stratégique qui engage la qualité de votre produit, vos finances, et même la souveraineté de vos données. Qu’il s’agisse des flagships commerciaux comme Claude Opus 4.8, Gemini 3.1 Pro et GPT-5.4, ou des challengers open source devenus redoutables (DeepSeek V4, GLM-5.1, Mistral Large 3, Qwen 3.7 Max…), notre rôle est de trier le hype du réel et de recommander ce qui fonctionne en production. Dans un marché où tout bouge chaque trimestre, la seule constante, c’est votre capacité à rester agile. Et c’est exactement là que Lonestone peut faire la différence.
Questions fréquentes
Quel est le meilleur LLM en 2026 ?
Au classement Chatbot Arena mi-2026, Claude Opus 4.8 (sorti mai 2026) d’Anthropic figure parmi les leaders, aux côtés de Gemini 3.1 Pro et GPT-5.4. Mais le “meilleur” LLM dépend du cas d’usage : Claude Opus excelle en raisonnement et en code, Gemini 3.1 Pro offre le meilleur rapport puissance/prix, et DeepSeek V4 rivalise sur la plupart des tâches pour 10-100x moins cher.
Quel LLM choisir pour un SaaS en 2026 ?
Pour un MVP rapide, Gemini 3.1 Pro ou GPT-5.4 offrent un excellent compromis simplicité-performance. En production à grande échelle, Claude Sonnet 4.6, Gemini 3 Flash ou Gemini 3.1 Flash-Lite maximisent le rapport qualité/coût. Pour la souveraineté européenne, Mistral Large 3 (Apache 2.0) est la référence. La meilleure architecture reste multi-modèles, capable de basculer d’un fournisseur à l’autre.
Comment choisir un LLM pour son projet ?
Le choix d’un LLM repose sur quatre critères : la qualité mesurée sur un jeu de tests représentatif du cas d’usage réel, le coût réel en production (multiplicateurs liés aux outils, à la longueur des prompts, aux appels successifs), l’écosystème (SDK, observabilité, support MCP) et la souveraineté des données. Construire un jeu de tests métier et comparer plusieurs modèles sur ce jeu est plus fiable qu’un benchmark générique.
Quels sont les 4 grands types de LLM en 2026 ?
On distingue quatre grandes familles de LLM : les modèles propriétaires fermés (GPT-5.4, Claude Opus 4.8, Gemini 3.1 Pro), les modèles open source poids ouverts (Llama 4, Mistral Large 3, DeepSeek V4), les modèles de raisonnement (o3, DeepSeek-R1, Magistral), et les modèles spécialisés (Mistral OCR, Mistral Embed, modèles de vision ou de code).
Quel est le prix d'un LLM en 2026 ?
Les tarifs varient considérablement : de 0,14 $ par million de tokens en entrée pour DeepSeek V4 Flash à 25 $ par million de tokens en sortie pour Claude Opus 4.8, soit un écart de près de 900x. Les coûts d’inférence baissent d’environ 10x par an à qualité équivalente. Pour estimer le coût réel selon le volume, utilisez le simulateur de coûts IA.
Quel est le meilleur LLM open source en 2026 ?
Pour les performances pures, GLM-5.1 (744B paramètres, MIT, avril 2026) atteint 58,4 % sur SWE-bench Pro, surpassant les modèles commerciaux. Mistral Large 3 (675B, Apache 2.0) reste la référence européenne pour la souveraineté. DeepSeek V4 (avril 2026) offre le meilleur rapport coût/performance avec ses variantes Pro et Flash, et Llama 4 Scout propose une fenêtre de contexte record de 10 millions de tokens.
Existe-t-il une alternative au LLM ?
Oui : pour des tâches qui ne nécessitent pas de génération de texte fluide, des alternatives existent. Les SLM (Small Language Models, comme Ministral 3) sont plus rapides et moins coûteux. Les modèles spécialisés (Mistral OCR pour l’extraction, modèles de classification supervisés) battent souvent un LLM généraliste sur leur tâche. Combiner LLM et système de règles métier reste souvent la meilleure approche.
Faut-il privilégier un LLM européen pour un SaaS français ?
Privilégier un LLM européen comme Mistral Large 3 ou EuroLLM se justifie quand les données traitées sont sensibles, soumises au RGPD ou à des obligations sectorielles (santé, défense, secteur public). Pour la performance pure, les modèles américains restent souvent en avance, mais l’écart se réduit chaque trimestre. Une architecture multi-modèles permet de combiner les deux selon la sensibilité des données.
