Évaluer votre IA : framework pour fiabiliser vos modèles
19 min de lecture
Mis à jour le
Lancer un produit IA, c’est accepter d’évoluer dans un système mouvant : modèles qui changent, prompts qui vieillissent, comportements imprévisibles, intégrations sensibles. Pourtant, une étape reste largement sous-estimée : évaluer systématiquement son système d’IA. Sans cadre d’évaluation solide, difficile de prouver que le modèle répond vraiment bien, d’anticiper les dérives ou de sécuriser les évolutions techniques. C’est le point aveugle qui fait vaciller la plupart des projets.
Ce qu’il faut retenir sur l’évaluation d’une IA
L’évaluation est le maillon manquant de la plupart des projets IA : sans cadre structuré, on reste dans l’illusion du “ça marche en dev” et on ne voit ni les dérives ni les régressions.
Un bon framework repose sur un dataset pertinent, pas massif : 30 à 50 cas bien choisis, annotés et évolutifs valent mieux que 500 exemples génériques.
Les bonnes métriques vont bien au-delà de l’accuracy : pertinence, ton, concision, toxicité, temps de réponse et coût par requête donnent une vision 360° de la qualité.
L’évaluation des agents IA exige une approche spécifique : évaluer la trajectoire complète (raisonnement, appels d’outils, décisions intermédiaires) devient indispensable pour les systèmes agentiques, au-delà du simple résultat final.
L’évaluation doit être continue, pas ponctuelle : tests réguliers sur votre dataset + sampling des requêtes réelles transforment l’IA en produit piloté, pas en boîte noire.
Le coût d’un framework d’évaluation est faible comparé au coût de l’absence d’évaluation : quelques jours pour le mettre en place, des heures par semaine pour le suivre… et en face, des semaines de debug, des utilisateurs perdus et une crédibilité entamée.
Pourquoi l’évaluation est le maillon manquant de vos projets IA
Le syndrome du “ça marche en dev”
La plupart des équipes qui intègrent de l’IA générative se concentrent sur la mise en œuvre fonctionnelle : le modèle répond, le RAG récupère les bonnes données, l’interface est fluide. Mais une fois en production, les choses se corsent.
Sans système de monitoring et d’évaluation, impossible de vérifier objectivement que tout fonctionne bien. On ne peut pas mesurer la pertinence des réponses, détecter les dérives, ou anticiper les problèmes avant qu’ils n’impactent les utilisateurs. C’est comme piloter un avion sans instruments de bord : tant que le ciel est dégagé, ça passe. Dès que les conditions changent, c’est le crash assuré.
Cette phase de développement crée une illusion de maîtrise. Les développeurs testent leur système sur des cas qu’ils connaissent bien, avec des questions qu’ils ont eux-mêmes formulées. Mais les utilisateurs réels ne respectent jamais le script. Ils posent des questions ambiguës, mélangent plusieurs intentions dans une même requête, font des fautes de frappe, ou utilisent un vocabulaire métier que personne n’avait anticipé. C’est là que tout se joue.
Le testing manuel d’un système IA souffre de plusieurs biais structurels. D’abord, l’effet “happy path” : on teste naturellement les cas qu’on sait fonctionnels. Ensuite, la fatigue cognitive : au-delà de 20-30 tests, l’attention baisse et les patterns problématiques passent inaperçus. Enfin, le biais de confirmation : quand on a passé des semaines à développer un système, on veut inconsciemment qu’il fonctionne.
Un framework d’évaluation automatisé élimine ces biais en appliquant systématiquement les mêmes critères, toujours avec la même rigueur, sur des volumes de tests impossibles à gérer manuellement.
Le piège du changement de modèle
Prenons un cas classique : vous commencez vos tests sur un modèle state-of-the-art comme GPT-5.5. Les résultats sont excellents. Mais pour des raisons de coûts, de souveraineté ou de performance, vous décidez de migrer vers un modèle plus économique, par exemple Mistral Small 4, hébergé en France.
Sans framework d’évaluation, vous ne pourrez ni mesurer ni prouver l’impact de ce changement. Vous risquez de dégrader l’expérience utilisateur sans même vous en rendre compte, ou à l’inverse de sous-estimer les capacités du nouveau modèle et de passer à côté d’optimisations possibles.
Les modèles évoluent à un rythme soutenu. OpenAI a lancé GPT-5.5 en avril 2026, avec ses déclinaisons Thinking, Pro et Instant. Mistral AI propose Mistral Small 4, un modèle unifié combinant raisonnement, multimodal et codage agentique. Anthropic fait évoluer régulièrement Claude, aujourd’hui en version Opus 4.8. Chaque mise à jour peut modifier subtilement le comportement de votre système. Un prompt qui fonctionnait parfaitement peut produire des résultats légèrement différents après une update. Comment le savoir sans système d’évaluation ?
Cas concret : Lors du développement de l’assistant IA pour Dessouter Tools, un système d’évaluation robuste a permis de tester le bon fonctionnement du RAG sur des questions métier complexes, mobilisant à la fois des API internes et de la documentation technique. Ce dispositif a été déterminant pour ajuster les configurations et améliorer les scores en continu, évitant ainsi des régressions lors des évolutions du système.
L’évaluation permet aussi de monitorer les changements de performance quand vous modifiez un prompt, changez de modèle, ou ajustez les données de contexte. C’est votre assurance qualité.
La pression réglementaire qui monte
Au-delà des enjeux techniques, la dimension réglementaire est désormais une réalité. L’AI Act européen est entré en application progressivement : les interdictions sur les systèmes à risque inacceptable sont effectives depuis février 2025, les règles de gouvernance et les obligations pour les modèles d’IA à usage général s’appliquent depuis août 2025. L’échéance majeure initialement prévue pour le 2 août 2026 a fait l’objet d’un report de 16 mois négocié en mai 2026, repoussant l’entrée en vigueur des exigences pour les systèmes IA à haut risque (Annexe III). Lorsque ces règles s’appliqueront, elles imposeront des obligations de gestion de la qualité, de documentation technique, de traçabilité et de supervision humaine. Les sanctions peuvent atteindre 35 millions d’euros ou 7 % du chiffre d’affaires mondial. Même pour les applications à moindre risque, la capacité à prouver que votre système fonctionne correctement devient un argument commercial décisif.
Vos clients commencent à poser des questions : comment garantissez-vous la qualité des réponses ? Quels mécanismes de contrôle avez-vous mis en place ? Que se passe-t-il en cas de dérive ? Un framework d’évaluation documenté et traçable n’est plus un “nice to have”, c’est une exigence du marché.
Les trois piliers d’un framework d’évaluation IA efficace

Construire un dataset d’évaluation pertinent
Votre dataset d’évaluation, c’est votre benchmark interne. Il doit être diversifié pour couvrir un maximum de cas de figure (questions simples, complexes, edge cases, requêtes ambiguës), de qualité avec des annotations soignées et idéalement validées humainement, et évolutif pour s’enrichir au fur et à mesure avec les données du terrain.
Quelle taille minimale ? À partir de 10 entrées, vous avez déjà un premier socle intéressant. Mais pour un système en production, visez plutôt 30 à 50 exemples bien choisis. Plus le dataset est volumineux, plus chaque évaluation coûtera cher en temps et en ressources — l’enjeu est donc de maximiser la pertinence plutôt que la quantité.
Pour identifier les edge cases importants, analysez les logs de production, les feedbacks utilisateurs, et les zones de flou de votre métier. Ce sont souvent les questions “bizarres” ou mal formulées qui révèlent les faiblesses d’un modèle.
La construction d’un bon dataset d’évaluation suit une méthodologie précise. Commencez par identifier les types de requêtes que votre système doit gérer. Pour un assistant de support client, cela pourrait inclure les demandes d’information produit, les questions de facturation, les problèmes techniques et les réclamations. Pour chaque catégorie, créez 5 à 10 exemples qui couvrent les variations réelles que vous observez.
N’oubliez pas les cas limites qui révèlent la robustesse de votre système : questions trop vagues (“Aidez-moi avec mon compte”), requêtes multiples en une (“Je veux modifier mon adresse et aussi comprendre pourquoi ma dernière facture est élevée”), formulations inhabituelles, ou encore requêtes hors périmètre que le système doit savoir refuser poliment.
Anatomie d’un bon exemple d’évaluation
Un exemple d’évaluation complet contient plusieurs éléments :
L’input utilisateur (la question ou requête)
Le contexte nécessaire (données client, historique, etc.)
La réponse attendue (gold standard)
Les critères d’évaluation spécifiques à valider
Le niveau de criticité (bloquant, important, mineur)
Par exemple : “L’utilisateur demande ‘Quelle est ma consommation ce mois ?’ → Le système doit récupérer les données du bon compte, calculer la période correcte, et présenter le résultat dans l’unité appropriée. Critère bloquant : exactitude des données. Critère important : clarté de la présentation.”
Définir des métriques au-delà de l’accuracy
L’accuracy (le modèle répond-il correctement ?) est un bon point de départ, mais elle ne suffit pas. Au-delà de la simple exactitude, vous devez surveiller la pertinence de la réponse pour vérifier que le modèle répond vraiment à la question posée, la tonalité pour vous assurer que le ton est aligné avec vos guidelines (professionnel, amical, technique), et la toxicité pour détecter d’éventuels contenus inappropriés ou biaisés. La concision compte également : une réponse trop verbeuse perd l’utilisateur. Enfin, n’oubliez pas les métriques opérationnelles comme le temps de réponse et le coût par requête, qui conditionnent la viabilité économique de votre produit.
Ces métriques vous permettent d’avoir une vision 360° de la qualité de votre IA, bien au-delà du simple “ça marche ou ça marche pas”.
La combinaison de ces métriques crée un score composite qui reflète la qualité globale de votre système. Un modèle peut avoir 95% d’accuracy mais générer des réponses deux fois trop longues, frustrant les utilisateurs. Un autre peut être ultra-concis mais manquer de pertinence sur certains cas complexes. L’objectif est de trouver l’équilibre optimal pour votre cas d’usage.
Certaines métriques peuvent être calculées automatiquement par des modèles d’évaluation (LLM-as-a-judge), d’autres nécessitent une validation humaine périodique. La clé est de définir clairement vos seuils acceptables : en dessous de quelle accuracy êtes-vous prêts à accepter ? Quel temps de réponse maximal tolérez-vous ? Quel budget par requête reste viable ?
L’approche LLM-as-a-judge s’est imposée comme standard, mais elle présente des biais documentés par la recherche récente : biais de position (les modèles frontières dépassent 50 % d’erreur sur certains tests de biais en production), biais de verbosité (les réponses longues sont systématiquement surévaluées), biais d’auto-préférence (un modèle favorise ses propres sorties), et contamination par fuite de préférences entre générateur et évaluateur. Pour les atténuer, utilisez des ensembles multi-juges (3 à 5 modèles différents avec vote majoritaire), randomisez l’ordre de présentation des réponses, privilégiez un modèle juge différent du modèle évalué, et appliquez des techniques de calibration et de correction des biais.
Pour implémenter votre framework d’évaluation, plusieurs outils peuvent vous aider. LangFuse est une plateforme open-source (licence MIT) pour le tracing, l’observabilité et l’évaluation des applications LLM. En février 2026, Langfuse a effectué une refonte architecturale majeure, passant à un modèle centré sur les observations immutables qui accélère les workflows d’évaluation (les évaluations s’exécutent désormais en secondes au lieu de minutes), avec support natif du Model Context Protocol pour l’intégration avec des agents IA, et versioning automatique des datasets. Confident AI / DeepEval propose un framework d’évaluation open-source avec plus de 50 métriques validées par la recherche, couvrant RAG, agents, chatbots, interactions multi-tours et sécurité, avec support multimodal (texte, images, audio), couplé à la plateforme cloud Confident AI pour la gestion de datasets et le monitoring en production. Braintrust combine évaluation et observabilité avec détection de hallucinations en temps réel et intégration native CI/CD, permettant de comparer prompts et modèles directement dans vos pull requests. Après une levée de fonds de 80 millions de dollars en février 2026, Braintrust a lancé Loop, un agent IA qui analyse automatiquement les logs de production pour identifier les patterns d’échec et suggérer des optimisations. La plateforme est utilisée par des entreprises comme Notion, Replit, Cloudflare et Dropbox. Ragas est devenu le standard open-source pour l’évaluation spécifique des pipelines RAG, avec des métriques dédiées comme la précision du contexte, le rappel, la fidélité et la pertinence des réponses. Ces plateformes permettent de centraliser vos métriques, d’automatiser les tests et de comparer facilement les versions de votre système.
Mettre en place un monitoring continu
L’évaluation n’est pas un événement ponctuel, c’est un processus continu. Une fois votre système en production, surveillez régulièrement les écarts de performance (un score qui chute brutalement doit déclencher une alerte), les nouvelles typologies de questions que vos utilisateurs peuvent poser, et l’évolution des coûts qui peut signaler un problème d’optimisation.
Les premiers signaux d’alerte ? Des variations importantes dans vos métriques clés, une augmentation des feedbacks négatifs, ou des temps de réponse qui se dégradent. Ne laissez pas ces signaux faibles devenir des problèmes majeurs.
Le monitoring continu s’appuie sur deux approches complémentaires. D’abord, l’évaluation automatisée régulière sur votre dataset de référence : relancez vos tests chaque semaine ou après chaque modification du système. Cela vous donne une baseline stable pour détecter les régressions. Ensuite, le sampling des requêtes réelles en production : prélevez aléatoirement 1% à 5% des interactions utilisateurs et soumettez-les à évaluation pour vérifier que les performances observées en test se maintiennent dans la vraie vie.
Cette double approche révèle souvent des surprises. Votre système peut performer brillamment sur le dataset d’évaluation mais rencontrer des difficultés sur des cas réels que vous n’aviez pas anticipés. Les utilisateurs sont créatifs dans leur façon d’interagir avec l’IA, et cette créativité génère constamment de nouveaux cas limites à capturer et intégrer dans votre dataset.
Évaluer les systèmes agentiques : un nouveau défi
Avec la montée en puissance des agents IA autonomes, l’évaluation dépasse le cadre des simples interactions question-réponse. Un agent IA enchaîne des étapes de raisonnement, appelle des outils, prend des décisions intermédiaires et interagit sur plusieurs tours de conversation. Les méthodes d’évaluation traditionnelles, qui traitent le système comme une boîte noire et vérifient uniquement le résultat final, échouent à identifier pourquoi un agent se trompe.
L’évaluation des agents repose sur deux types de métriques complémentaires. Les métriques de trajectoire analysent le chemin complet d’exécution : chaque étape de raisonnement, chaque appel d’outil, chaque décision. Elles permettent de déboguer et d’améliorer le processus en montrant comment l’agent travaille. Les métriques de résultat valident si l’agent atteint les objectifs métier attendus.
Les approches hybrides combinent un premier passage d’évaluation automatisée (LLM-as-a-judge) sur l’ensemble des sorties de l’agent, avec un routage des cas limites, des échecs et des décisions à fort impact vers des évaluateurs humains. Cette combinaison offre la vitesse de l’automatisation tout en maintenant une supervision humaine là où elle est indispensable.
Des benchmarks spécialisés se sont imposés pour évaluer ces systèmes : SWE-Bench Verified (résolution de problèmes GitHub réels sur 12 dépôts Python de référence), WebArena (tâches web réalistes dans quatre domaines), AgentBench (8 environnements différents), GAIA et TAU-bench. Ces benchmarks ont cependant révélé des failles en 2026 : contamination des données, reward hacking et dérive des environnements. Les praticiens privilégient désormais les évaluations internes sur des cas métier spécifiques plutôt que de se fier uniquement aux scores publics. Des techniques de red-teaming permettent aussi de tester la robustesse des agents face à des attaques comme l’injection de prompts, la manipulation d’outils ou l’injection d’environnement.
Ajuster, pas réentraîner : l’approche pragmatique
Contrairement aux modèles de machine learning classiques, les systèmes d’IA générative ne nécessitent généralement pas de réentraînement. L’enjeu est plutôt d’ajuster finement les paramètres : optimiser vos prompts, changer de modèle si nécessaire, améliorer le contexte fourni (sources documentaires, paramètres du RAG), ou affiner les règles métier.
Votre framework d’évaluation vous permet de mesurer l’impact de chaque ajustement et de valider que vous allez dans la bonne direction. C’est un cycle d’amélioration continue, pas une révolution à chaque itération.
Cette approche itérative transforme l’évaluation en véritable outil de pilotage produit. Vous identifiez une faiblesse sur une catégorie de questions ? Vous ajustez le prompt spécifiquement pour cette catégorie, relancez l’évaluation, et mesurez l’amélioration. Cette méthodologie crée un cercle vertueux : chaque problème détecté devient une opportunité d’amélioration mesurable.
Les ajustements les plus impactants concernent souvent l’architecture du prompt. Ajouter des exemples de réponses attendues (few-shot learning), structurer les instructions de manière plus claire, ou décomposer les tâches complexes en étapes intermédiaires peut transformer radicalement les performances sans changer de modèle. C’est l’équivalent du prompt engineering, mais piloté par les données plutôt que par l’intuition.
Les leviers d’optimisation dans l’ordre
Face à un problème de performance, voici les leviers à actionner dans l’ordre :
Améliorer le prompt : C’est le levier le plus rapide et le moins coûteux. Reformulez les instructions, ajoutez des exemples, clarifiez les attentes.
Optimiser le contexte : Si vous utilisez du RAG, améliorez la qualité des chunks récupérés, ajustez les paramètres de recherche (top-k, seuil de similarité), enrichissez votre base documentaire.
Ajuster la température : Réduisez-la pour plus de déterminisme, augmentez-la pour plus de créativité selon votre cas d’usage.
Changer de modèle : Seulement si les ajustements précédents ne suffisent pas. Le nouveau modèle doit être validé sur l’intégralité du dataset d’évaluation.
Fine-tuner : Option ultime, rarement nécessaire pour les cas d’usage standards. À réserver pour des besoins très spécifiques avec des données métier très particulières.
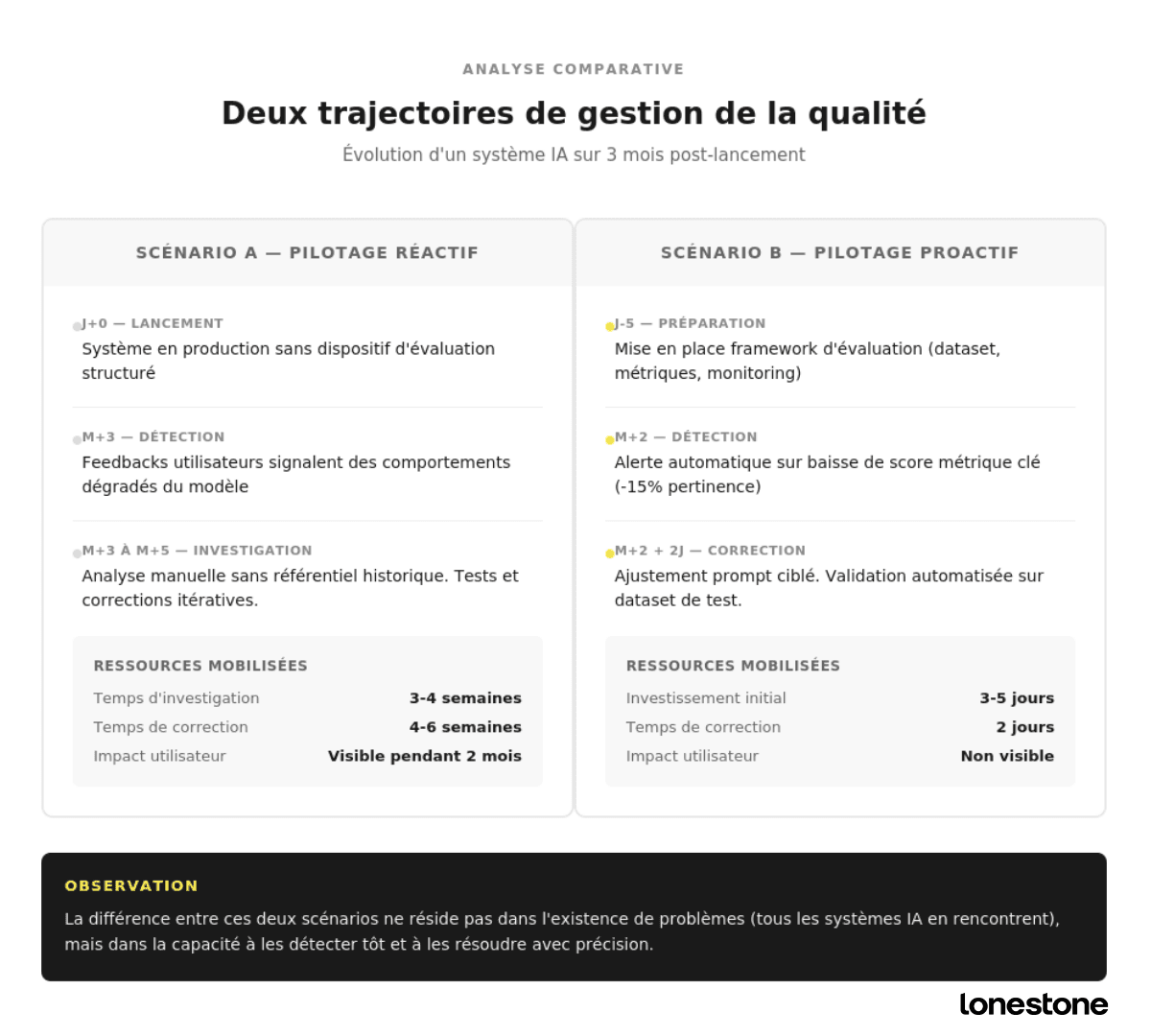
Combien ça coûte vraiment d’évaluer son IA ?
Budget et timing
Mettre en place un système d’évaluation ne peut pas se faire d’une traite. Il vaut mieux commencer tôt et petit, en y consacrant quelques jours lors du lancement du projet, puis prévoir un budget récurrent pour suivre et améliorer le système au fil du temps.
L’investissement initial est modeste — souvent entre 3 et 5 jours de travail — mais le retour sur investissement est immédiat : vous évitez les régressions coûteuses, vous gagnez en confiance, et vous accélérez vos itérations.
Concrètement, la phase initiale comprend la sélection de l’outil d’évaluation adapté à votre contexte, la construction du premier dataset avec 30 à 50 exemples, la définition des métriques et seuils de qualité, et la mise en place des dashboards de suivi. Ensuite, comptez une demi-journée par semaine pour le suivi et l’enrichissement continu du système.
Cette charge peut sembler élevée, mais elle se substitue largement au temps passé en debugging réactif, en investigation de problèmes remontés par les utilisateurs, et en refonte précipitée de fonctionnalités mal calibrées. L’évaluation transforme le temps de pompier en temps d’ingénieur : vous anticipez au lieu de subir.
Évaluation IA rétrospective : mieux vaut tard que jamais
Bonne nouvelle : un système d’évaluation peut être mis en place sur un projet IA existant, même s’il tourne depuis plusieurs mois sans monitoring. Vous ne disposerez pas des données historiques pour comparer, mais vous pourrez commencer à tracer et à piloter à partir de maintenant. L’essentiel est de ne pas attendre.
Si votre système est déjà en production, commencez par capturer une semaine de logs utilisateurs. Analysez les requêtes les plus fréquentes, identifiez les patterns émergents, et construisez votre dataset initial à partir de ces données réelles. C’est même souvent plus pertinent que de partir de cas théoriques, car vous capturez directement ce que vos utilisateurs demandent vraiment.
Le coût caché de l’absence d’évaluation IA
Imaginons deux scénarios. Dans le premier, vous lancez votre IA sans framework d’évaluation. Trois mois plus tard, vous recevez des plaintes utilisateurs. Vous réalisez que le modèle a dérivé, que certains prompts ne fonctionnent plus comme prévu. Vous devez tout reprendre de zéro, sans référentiel pour comprendre ce qui a changé. Le coût estimé ? Plusieurs semaines de développement, une perte de confiance utilisateur, et un risque réputationnel réel.
Dans le second scénario, vous intégrez l’évaluation dès le départ. Vous détectez rapidement une baisse de performance sur une métrique clé. En deux jours, vous ajustez le prompt problématique et validez la correction. Le coût estimé se limite à quelques heures de travail, sans aucun impact utilisateur.
La différence est nette. L’évaluation, c’est l’assurance qualité de votre produit IA. Au-delà du temps de développement économisé, c’est la crédibilité de votre solution qui est en jeu. Un produit IA qui déçoit ses premiers utilisateurs peine ensuite à reconquérir leur confiance, quel que soit le niveau de corrections apportées.
Trois principes pour réussir votre démarche d’évaluation IA
Commencez simple et itérez. Ne cherchez pas la perfection dès le départ. Un dataset de 10 exemples bien choisis vaut mieux qu’un tableur de 500 cas génériques. Lancez-vous avec les cas les plus critiques pour votre métier, validez que le système fonctionne, puis enrichissez progressivement.
Impliquez les métiers. L’évaluation ne doit pas être 100% automatisée. Prévoyez des revues humaines régulières pour valider que vos métriques reflètent bien la réalité terrain. Les équipes métier détectent des nuances qu’aucun algorithme ne capturera : une réponse techniquement exacte mais formulée de manière inappropriée pour le contexte, une information obsolète mais toujours valide d’un point de vue factuel, ou une tonalité légèrement décalée par rapport à votre image de marque.
Faites-en un rituel. Intégrez l’évaluation dans votre cycle de développement. Chaque sprint, chaque déploiement devrait inclure une passe d’évaluation. Ce n’est pas une tâche annexe qu’on case quand on a le temps, c’est un passage obligé avant toute mise en production. Exactement comme les tests unitaires dans le développement logiciel classique.
Ce qu’il faut retenir pour évaluer son IA
Mettre en place un framework d’évaluation n’est pas un luxe, c’est une nécessité stratégique pour tout projet IA sérieux. Cela vous permet de mesurer objectivement la qualité de vos modèles, d’anticiper les régressions avant qu’elles n’impactent vos utilisateurs, de sécuriser vos migrations techniques (changement de modèle, ajustements de prompts), et de piloter l’amélioration continue de votre produit.
L’évaluation transforme votre IA d’une boîte noire en un système maîtrisé et fiable. Et dans un domaine où la confiance est la clé de l’adoption, c’est un avantage compétitif décisif. Les organisations qui intègrent l’évaluation dès la conception de leur produit IA gagnent en agilité, en réactivité, et en capacité à prouver la valeur de leur solution. C’est la différence entre une démo impressionnante et un produit prêt pour le scale.
Vous souhaitez structurer votre démarche d’évaluation ou auditer votre système IA existant ? Découvrez notre offre d’accompagnement IA.
