Optimiser une API GraphQL à l’aide d’un cache serveur
Lonestone est une agence qui conçoit et développe des produits web et mobile innovants.
Nos experts partagent leurs expériences sur le blog. Contactez-nous pour discuter de vos projets !
En début d’année, sur le projet sur lequel je travaille, nous nous sommes confronté à des problèmes de performance sur notre API. Nous n’avions pas d’énorme dette technique, et employions de bonnes pratiques de développement, mais la base d’utilisateurs grossissait à un point où « bien coder » ne suffisait plus à faire tenir le serveur. Il a fallu s’attaquer sérieusement à cette problématique très souvent mise de côté : comment alléger la charge du serveur ?
Pourquoi c’est pas facile et quelles sont les solutions ?
Notre API est une API GraphQL basée sur Express, utilisant Mongo comme base de données (mais cet article est valable pour n’importe quel type de base de données). Le service est lié à des événements en direct, ce qui signifie que l’on fait face à d’énormes pics de requêtes simultanées. De plus, les entités en base ont beaucoup de dépendances entre elles, liées aux permissions des utilisateurs. De fait, pour récupérer un élément, il est souvent nécessaire d’aller chercher ses parents ou d’autres données liées à l’utilisateur pour calculer chaque resolver. Et je ne vous parle pas de la page d’accueil qui affiche du contenu dynamique en fonction de ce qui est publié, les dates des événements, et les préférences de chaque utilisateur ! Bref, de très nombreux appels vers la base de données pour chaque requête, tous absolument nécessaires. Ça passe pour 100 utilisateurs, mais à partir de 600, tout s’effondre, même avec un cluster de 5 nœuds.
Optimiser ce genre d’API n’est pas une tâche facile. Car GraphQL n’a pas la même logique que REST : une Query est un arbre composé de plusieurs petits nœuds, que l’on ne peut pas calculer à l’avance. Chacun de ces nœuds est un resolver, avec sa propre logique, qui va faire ses propres micro-appels en base de données. Impossible donc de faire un seul énorme appel parfaitement optimisé en tout début de requête ! Il faut forcément que ce soit modulable.
Heureusement, il existe un outil puissant pour résoudre ce problème : le cache serveur. L’optique est d’éviter de faire des appels base de donnée (BDD), pour récupérer le résultat dans Redis à la place. C’est un gain de performance non négligeable ! Et Apollo propose des outils bien pratiques pour cela. On trouve ainsi trois niveaux de cache : Cache HTTP, Dataloaders, et Datasources. Cette première partie sera consacrée au premier.
Server-side caching avec Redis
Le cache HTTP est le plus haut niveau de cache côté serveur. L’idée ici est, pour deux appels identiques au serveur, de conserver le résultat du premier et le renvoyer au deuxième. On économise littéralement l’intégralité de la requête !
C’est plaisant sur le papier, mais bien sûr il y a un peu de complexité derrière. Les données doivent être maintenues en cache pour un certain temps seulement. Certaines expirent plus rapidement que d’autres. Certaines dépendent de l’utilisateur qui fait la requête. Et certaines ne doivent même surtout pas être mises en cache ! Comment configurer cela ?
Apollo offre une élégante solution de server-side caching pour cela. Celle-ci utilise directement le schéma GraphQL pour spécifier la durée et l’étendue du cache, pour chaque type de donnée. Simple à écrire, et tout autant à lire.
Voyons comment mettre cela en place. Le plugin responseCachePlugin doit être initialisé à la construction de l’ApolloServer, en paramétrant la ressource de cache à utiliser. Ici, ça sera un cache Redis.
Une fois ceci mis en place, il suffit de configurer le schéma directement dans les fichiers .graphql, en utilisant le tag cacheControl, pour mettre en cache les requêtes entières. Le fonctionnement est celui-ci :
maxAge indique la durée de validité du cache en secondes. Par défaut, elle vaut 0.
scope prend la valeur PUBLIC ou PRIVATE pour indiquer si un cache est commun à tous les utilisateurs, ou s’il est unique à chacun. Par défaut, il vaut PUBLIC.
Le cache prend effet sur toute la requête (et non les resolvers, nous verrons dans les parties suivantes comment le faire). La valeur maxAge pour la requête est celle du plus petit maxAge présent dans l’arbre, et le scope est PRIVATE si une seule des propriétés l’est.
Les types primitifs héritent de la configuration de leur parent direct. Les types complexes quant à eux prennent les valeurs par défaut (0, PUBLIC) ou celles écrites dans le schéma. Il vaut donc mieux spécifier le cache sur tous les types existants.
En prenant bien le temps de passer sur tout le schéma, on a déjà un cache bien performant ! Dans le cas du projet où je l’ai mis en place, je suis parti sur une durée de 60 secondes par défaut, 20 ou 30 pour les données ayant besoin d’être rafraîchies rapidement, 240 voire 300 pour les éléments rarement mis à jour. Ce n’est pas nécessaire d’avoir un cache trop long, et quand il y a beaucoup d’appels ça fait déjà une différence.
Il reste quelques configurations à ajouter au plugin (toujours dans les options de la fonction d’initialisation) :
sessionId: Fonction prenant en paramètre la requête, et retournant l’id unique de l’utilisateur. Nécessaire pour identifier l’utilisateur et ainsi faire fonctionner le scope PRIVATE. L’id peut être un token JWT dans les header, ou même un id présent dans le context graphQL.
shouldReadFromCache et shouldWriteToCache : Fonctions asynchrone prenant en paramètre la requête et le contexte, et retournant un booléen indiquant respectivement si la requête peut être lue depuis le cache, et conservée dans le cache. Certains cas d’usage en effet peuvent nécessiter de contourner le cache, comme un backoffice par exemple (où l’on veut la donnée la plus à jour possible). Idem pour certains utilisateurs, comme les admins, qui ont accès à des données “non publiées” qui ne doivent pas être intégrées dans le cache public. Ces fonctions permettent donc de se baser sur un header, ou des infos de l’utilisateur, pour ignorer le cache.
Voici un exemple de configuration du cache avec ces paramètres :
Règles dynamiques de cache
Enfin, on peut affiner encore plus loin en spécifiant des règles de cache dynamiques à l’intérieur des resolvers. Par exemple, supposons que pour une même entité, on souhaite avoir un cache public par défaut, mais privé si elle remplie certaines conditions ? Ou que si elle est dans un certain état, elle doit être en cache moins longtemps ?
Pour mettre en place ce genre de logique, On utilise cacheControl depuis les GraphQLResolveInfo, fournies en paramètre dans chaque resolver.
On a à présent un cache sur des requêtes entières !
Mais il a ses limites. Dès que la requête est privée, elle est exécutée par chaque utilisateur. Et pour certaines données critiques, il n’est pas très long. Or, avec ce cache, c’est tout ou rien : soit la requête entière est en cache, soit non. Ce qui signifie que si une requête lourde inclut ne serait-ce qu’une propriété à faible cache, tout l’arbre de resolver est exécuté. Il faudrait pouvoir alléger les requêtes elle-mêmes, morceaux par morceaux.
À présent, on souhaiterait avoir un cache plus fin sur des morceaux de requête. Pour cela, nous aurons recours aux Dataloaders.
À quoi sert un Dataloader ?
Les dataloaders sont des outils GraphQL permettant de mémoriser dans une requête une entité déjà récupérée depuis la base de données. Exemple : supposons une liste d’entités A, B, C, etc, ayant chacune un resolver attachedTo pointant sur un même objet X. Sans dataloader, ce resolver sera exécuté pour chaque entité, faisant ainsi plusieurs fois le même appel vers la base de données !
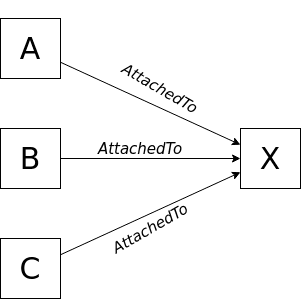
Et les resolvers ne sont que l’exemple le plus basique. Sur mon projet actuel on a sans cesse besoin d’accéder à certaines entités parentes afin de déterminer l’accès à certaines informations, voire calculer certaines propriétés (« L’élément dont fait partie cet item est-il enfant d’un événement en cours ? », « Quel est l’organisme propriétaire et l’utilisateur en fait-il partie ? », etc). Si à chaque fois que l’on a besoin d’une ressource, on va la chercher en base de données, on fait vite grimper le nombre de requêtes.
Les dataloaders répondent à cette problématique. Un dataloader est associé à une collection (en Mongo, une table pour SQL) et permet de récupérer une ou plusieurs entités depuis leurs ids. Il conserve le résultat tout au cours de la requête. Si la même ressource est demandée, il pourra la retourner sans la chercher en base de donnée. De cette manière, le dataloader garantit qu’une requête BDD n’est pas exécutée plus de fois que nécessaire.
Mise en place
Pour construire un dataloader, on utilise la classe Dataloader dont le constructeur a essentiellement besoin de deux éléments :
Une fonction de batch retournant, pour une liste de clés (de type K), les valeurs correspondantes. La raison pour laquelle cette fonction prend et retourne une liste est pour permettre au dataloader de faire du batching.
Dans les options, une fonction de transformation de clé (K) en chaîne de caractère. Si vos clés sont déjà des strings, cette fonction n’est pas requise. Mais elle est indispensable pour Mongo où l’on manipule des ObjectId.
Voici un exemple de fonction générique construisant un dataloader sur une collection Mongo (en utilisant mongoose). Le type de clé est ici ObjectId.
Cette fonction permet de créer une liste de plusieurs loaders pour les données les plus demandées. L’idéal ensuite est d’instancier ces dataloaders depuis le context GraphQL. Dans le constructeur de ma classe GraphQLAPIContext, j’ai ainsi ajouté :
De cette façon je peux accéder à l’instance des loaders depuis n’importe quel resolver. Un loader propose deux fonctions principales : load, pour récupérer un donnée par une clé, et loadMany pour en récupérer plusieurs.
Ainsi dans une requête, dès qu’un document est chargé depuis un nœud GraphQL, il sera accessible pour tous les autres sans avoir besoin de refaire une requête Mongo.
Toutefois, cela n’est valable que pour une seule requête. Les dataloaders sont réinitialisés à chaque appel. Donc si on a énormément d’appels simultanés (et dans ma situation, c’est le cas), on conservera un nombre conséquent de requêtes à la BDD. Y a t-il moyen de conserver le résultat d’une requête BDD sur plusieurs appels API ?
À présent nous allons utiliser les data sources pour mettre en cache des entités entre plusieurs requêtes.
Les data sources sont des classes d’Apollo qui servent de connecteur entre graphQL et une base de données ou une API Rest. Ici ce qui nous intéresse, c’est leur capacité de mettre en cache leur ressources. On est donc au niveau de cache le plus bas : cache sur les entités stockées en base de données !
Utilisation
Ils sont un peu plus complexes à mettre en place que les dataloaders. Tout d’abord, il faut utiliser une classe appropriée au type de base de donnée avec laquelle on souhaite interagir (SQL, Mongo, REST…). Dans les exemples qui suivent, j’utiliserai MongoDataSource, mais les logiques avec d’autres sont équivalentes.
Comme pour les dataloaders, je suggère de créer une classe générique héritant ou encapsulant (battez-vous) la data source. Cela permet de faire facilement le lien avec mongoose, et de donner une TTL (temps de cache, en seconde) différente selon la collection, ainsi que de l’hydratation de donnée. En effet la MongoDataSource passe directement par Mongo, et non les fonctions de mongoose. Ce qui est bien plus optimal, mais en contrepartie enlève certains raccourcis (comme la propriété id pour obtenir l’id sous forme de string).
Note : Ne vous souciez pas des LeanDocument, c’est une interface propre à mongoose
Comme vous pouvez le voir, on retrouve les mêmes fonctionnalités que les dataloaders : récupérer un objet par id, ou une liste. Ces deux fonctions vont se charger de vérifier si la donnée est présente dans le cache et n’est pas expirée. Si oui, elle la retourne, si non, elle fait la requête. Sur plusieurs appels d’API, on a donc un seul qui va peupler le cache pour tous les autres ! La troisième fonction, find, peut être parfois utile, mais on verra ensuite une manière plus efficace de mettre en cache des requêtes complexes.
Pour initialiser ces data sources, nous avons besoin d’une factory qui va retourner un objet dont les clés sont associées à des data sources pour les collections respectives.
Cette fonction va ensuite être passée à l’initialisation du serveur Apollo, avec le cache redis (le même que celui créé pour le cache HTTP). Notez que l’on renseigne la fonction sans l’appeler.
Apollo se chargera lui-même de construire et initialiser les data sources, et les ajouter au contexte. Chaque resolver pourra ainsi y accéder.
Léger piège : pour peu que vous utilisiez Typescript, vous vous heurterez à un problème à la construction du contexte graphQL. En effet vous ne pourrez pas renseigner la propriété dataSources dans le constructeur, car c’est Apollo qui l’ajoute après ! C’est pourquoi vous avez besoin de deux classes de contexte : une sans dataSources, utilisée que pour la construction, et une avec, accessible depuis les resolvers.
Il ne manque plus qu’une dernière chose. Maintenant que nous avons des entités mises en cache, avec des durées d’une minute environ, que risque t-il de se passer à l’édition ou à la suppression ? Oui, les utilisateurs vont récupérer l’ancienne version toujours en cache, ce qui n’est pas bon du tout ! Pour nettoyer le cache, il faut penser à faire dans les mutations d’édition ou suppression :
Afin qu’il soit à jour au prochain appel.
Qu’en est-il des dataloaders ?
Vous l’aurez peut-être deviné, les data sources remplissent la même fonction que les dataloaders, mais sur plusieurs requêtes. Ces derniers deviennent donc pratiquement obsolètes. Il est tout à fait possible de choisir l’un ou l’autre.
Il est malgré tout possible de les combiner. Notamment si vous souhaitez limiter les appels au cache dans une seule requête. La logique à suivre, c’est de faire en sorte que les dataloaders utilisent les datasources. Les resolvers se contentent ainsi d’appeler les dataloaders, qui derrière appelleront les data sources. Pour cela, l’ordre dans lequel j’ai procédé est :
Construire d’abord les dataloaders dans le contexte, sans datasource
Construire les datasource
Dans la fonction initialize d’un datasource, surcharger le dataloader correspondant (trouvable dans le contexte) pour qu’il fasse appel à l’instance du data source
Mettre en cache des requêtes complexes
Mettre en cache des entités par id, c’est pratique. Mais c’est loin de constituer les requêtes les plus lourdes, ni les plus fréquentes. On aimerait pouvoir mettre en cache des recherches plus complexes. C’est encore possible avec les data sources ! Pour cela, il va falloir mettre un peu la main à la pâte, et construire notre propre Data Source. On procède en héritant de la classe d’Apollo DataSource. Dans celle-ci, nous pouvons surcharger la méthode initialize pour récupérer le cache qui servira dans des fonctions personnalisées. Ces fonctions suivent toutes la même logique : on vérifie si la clé existe dans le cache, si oui on la retourne, si non on va faire l’appel en base de données et on écrit le résultat en cache avec un TTL adéquat.
Note : Dans cet exemple, on ne retourne pas les entités entières, mais leurs ids. En effet, vu qu’on a des data sources qui permettent déjà de récupérer les entités depuis le cache par id, cela ne sert à rien de les stocker une deuxième fois
Il ne reste plus qu’à ajouter ce data source fait maison à notre factory.
Il est ensuite accessible dans les Query GraphQL depuis le contexte.
Avec ces trois outils, Cache HTTP, Dataloaders, et Data sources, vous disposez de leviers puissants pour améliorer les performances d’un serveur graphQL. Toujours dans l’optique de limiter les appels faits à la base de donnée. Pour résumer chaque niveau :
Le Cache HTTP met en cache le résultat de requêtes entières sur des laps de temps variables
Les dataloaders garantissent que les recherches par ID sur la BDD ne sont exécutées qu’une seule fois lors d’un appel de l’API
Les data sources mettent en cache des entités de la BDD ou des résultats de recherche spécifiques pendant des laps de temps variables
Cependant le nombre de requêtes vers la base de données n’est pas l’unique charge qui pèse sur un serveur !
Il y a d’autres pistes d’amélioration qui sont aussi à envisager :
Utilisez un ORM à jour. Cela peut vraiment faire la différence.
Désactivez les hydratation de votre ORM que vous n’utilisez pas. Les fameux LeanDocument que vous pouvez voir dans ces exemples sont une classe de mongoose, qui possède une option pour désactiver les nombreuses fonctionnalités de sa classe de Document par défaut. Une charge non négligeable qui se retire « facilement » (quand c’est fait en amont).
Alternativement, se passer de l’ORM et faire directement des appels en base de donnée peut s’avérer efficace. C’est ce que font les data sources !
Utilisez des indexes dans votre base de données là où c’est pertinent.
Évitez les validations de donnée superflues. C’est tentant d’être rigoureux dans chaque route, et de vouloir vérifier que la donnée est absolument cohérente. Mais si cela coûte plusieurs requêtes BDD appelées fréquemment, ce n’est peut-être pas l’idéal. Il peut être parfois plus avantageux de laisser un peu de flexibilité, et partir du principe qu’une fonction n’est appelée que dans un contexte qui a déjà été validé en amont.
Mettre en place du cache est une première étape pour l’optimisation des performances du serveur. Il convient ensuite aux développeurs de l’utiliser judicieusement pour faire le maximum d’économie sur les appels les plus utilisés.





